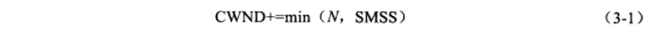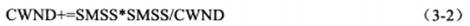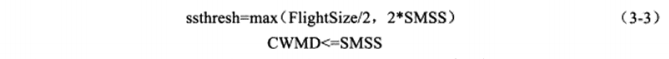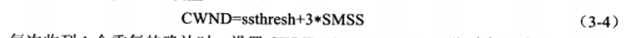Linux高性能服务器编程 第1章 TCP/IP 协议族 Internet使用的主流协议族是TCP/IP协议族,它是一个分层,多协议的通信体系。本章简单介绍其中几个相关协议: ICMP协议,ARP协议和DNS协议。
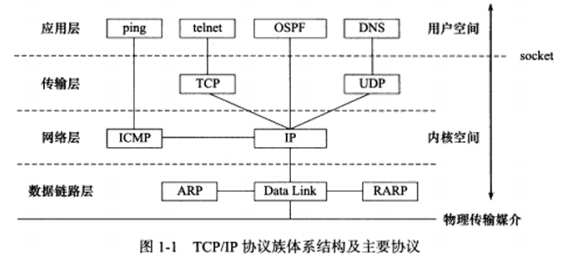
1.1 TCP/IP协议族体系结构以及主要协议 四层模型,数据链路层,网络层,传输层和应用层。
a) 数据链路层
实现了网卡接口的网络驱动程序,以处理数据在物理媒介上的传输。隐藏了不同物理网络的细节,为上层协议提供一个统一的接口。
该层的两个常用协议,ARP协议 (Address Resolve Protocol, 地址解析协议) 和 RARP协议 (Reverse Address Resolve Protocol, 逆地址解析协议) 。实现了IP地址和机器物理地址之间的相互转换。
网络层使用IP地址寻址一台机器,而数据链路层使用物理地址寻址一台机器,网络层需要先将目标机器的IP地址转换成其物理地址,才能使用数据链路层提供的服务,这就是ARP协议的用途。
b) 网络层
网络层实现数据包的选路和转发。WAN (Wide Area Network, 广域网) 使用众多分级的路由器来连接分散的主机或 LAN**(Local Area Network, 局域网)**。两台主机一般不是直接相连的,而是通过多个中间节点(路由器)连接的。网络层的任务就是选择这些中间节点。网络层对上层细节隐藏这些细节,在上层看来,通信的双方是直接相连的。
网络层最核心的协议,IP协议 **(Internet Protocol, 因特网协议)**。IP协议根据数据包的目的IP地址来决定如何投递他。如果不能直接发送给目标主机,IP协议为它寻找一个合适的下一跳路由器,并将数据包交给路由器来转发,多次重复这一过程。
另一个重要协议,ICMP协议 **(Internet Control Message Protocol, 因特网控制报文协议)**。它是IP协议的重要补充,主要用于检测网络连接。
8位类型用于区分报文类型。比如目标不可达(类型值为3),重定向(类型值为5),目标是否可达(类型值为8) 8位代码进一步细分不同条件。16位检验和字段对整个报文进行循环冗余校验,以检验报文在传输过程中是否损坏。
c) 传输层
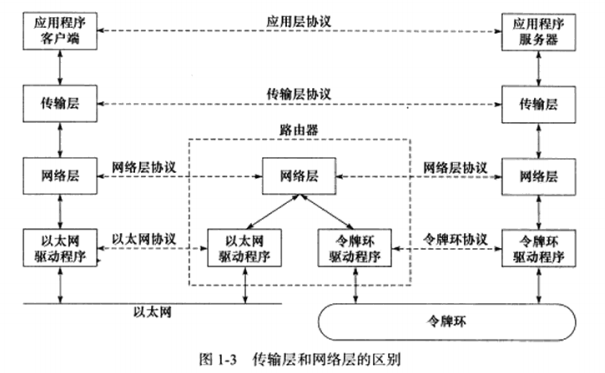
传输层位两台主机提供端到端的通信。简单来说不考虑IP协议的中转过程了,这些也在网络层中向上隐藏细节了。下图实线箭头表示协议族各层中之间的实体通信,水平虚线表示逻辑通信线路。
传输层主要有三个协议:TCP协议,UDP协议,SCTP协议。本书不讨论SCTP协议,TCP和UDP协议在UNP中已经比较熟悉了。
d) 应用层
应用层负责处理应用程序的逻辑。前面的三个层处理网络通信细节,这部分稳定高效,因此它们在内核空间中实现。而应用层则在用户空间中实现。
应用层协议很多,图1-1中列举了其中几个:
ping是应用程序,不是协议,他利用ICMP报文检测网络连接。
telnet协议是一种远程登陆协议,它使我们能在本地完成远程任务。
OSPF (Open Shortest Path First, 开放最短路径优先) 协议是一种动态路由更新协议。
DNS (Domain Name Service, 域名服务) 协议提供机器域名到IP地址的转换。
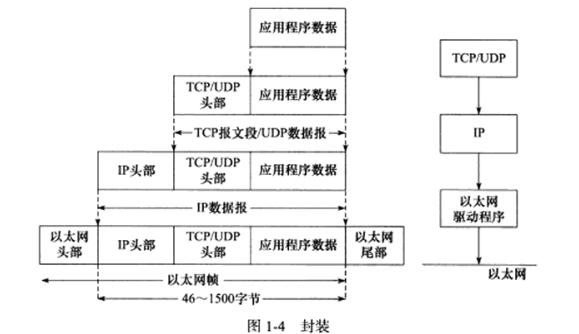
1.2 封装 程序数据在发送到物理网络上之前,将沿着协议栈从上往下传递。每层协议都将在上层数据的基础上加上自己的头部信息,以实现该层的功能呢,这个过程称为封装。
就跟套娃差不多 (
程序数据到 -> TCP/UDP报文段 -> IP数据报 -> 以太网帧
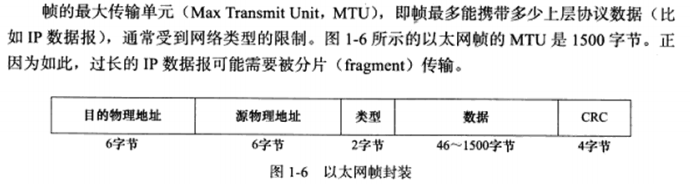
经过数据链路层封装的数据称为帧。传输媒介不同,帧的类型也不同。比如以太网上传输的是以太网帧,而令牌环网络上传输的是令牌环帧。以太网帧的封装格式如下图。类型字段后面讨论,4字节CRC字段对帧的其他部分提供循环冗余校验。
帧才是最终在物理网络上传送的字节序列。至此,封装过程完成。
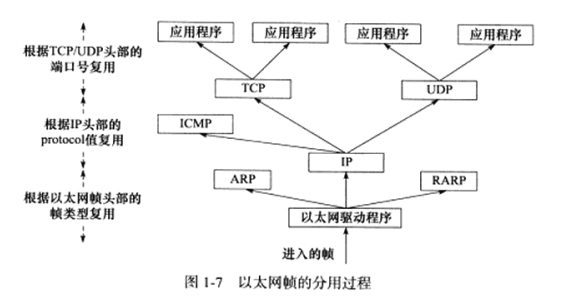
1.3 分用 帧到达目的主机后,将沿着协议族自底向上依次传递。各层协议依次处理帧中本层负责的头部数据,以获取所需信息,并最终将处理后的帧交给目标应用程序。这个过程称为分用。分用时依靠头部信息中的类型字段实现的。
比如拿以太网帧举例说,如果类型字段值为0x800,则帧的数据部分为IP数据报,以太网驱动程序将帧交给IP模块处理;若类型字段值为0X806,则帧的数据部分为ARP请求或应答报文,交给ARP模块来处理;0X835则,RAPA请求或应答,则交给RAPA模块。IP的protocol和TCP/UDP的端口号同理。
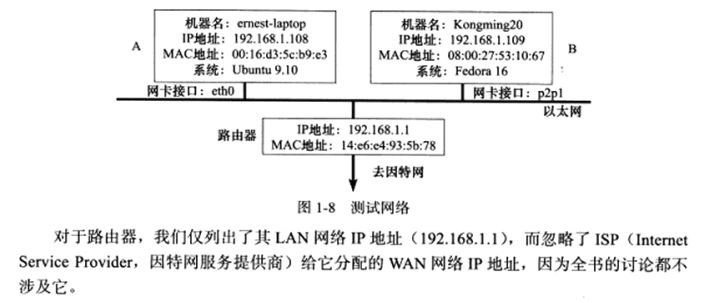
1.4 测试网络 本书实验所用的测试网络。作者编写的多个客户端,服务器程序都是使用该网络来调试和测试的。
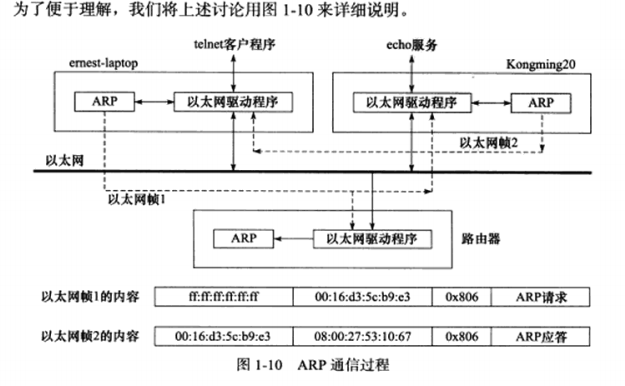
1.5 ARP协议工作原理 ARP协议能实现任意网络层地址到任意物理地址的转换。其工作原理:主机向自己所在的网络广播一个ARP请求,该请求包含目标机器的网络地址。此网络上的其他机器都将收到这个请求,但只有被请求的目标机器会回应一个ARP应答,其中包含自己的物理地址。
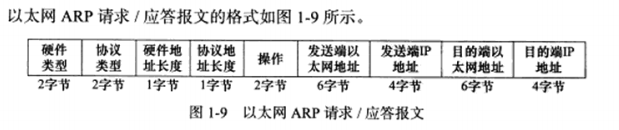
a) 以太网ARP请求/应答报文详解
每个字段的具体值介绍见p9
ARP请求/应答报文的长度为28字节。如果再加上以太网帧头部和尾部的18字节,则一个携带ARP请求/应答报文的以太网帧长度为46字节。
b) ARP高速缓存的查看和修改
通常ARP维护一个高速缓存,其中包含经常访问(比如网关地址)或最近访问的机器的IP地址到物理地址的映射。这样就避免了重复的ARP请求,提高了发送数据包的速度。
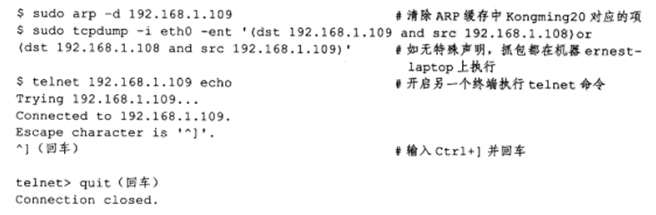
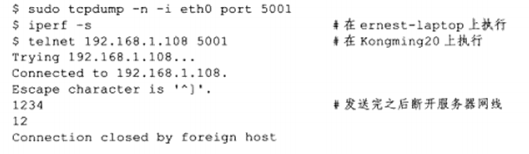
Linxu下可使用arp命令来查看和修改ARP高速缓存,比如ernest-laptop(作者测试网络中的主机)某一时刻的ARP缓存内容如下(使用arp-a命令):
第一项描述的是另一台测试机器Kongming20,第二项描述的是路由器。下面两条命令分别删除和添加一个ARP缓存项:
c) 使用tcpdump观察ARP通信过程
在ernest-laptop上执行telnet命令登录Kongming20的echo服务,并用tcpdump抓取这个过程中两台测试机器之间交换的以太网帧。具体操作如下:
在执行telnet命令之前,应先清除ARP缓存中与Kongming20对应的项,否则ARP通信不被执行。ARP通信在TCP连接建立之前就已经完成,我们不关心telnet中的内容,在它建立连接成功后就可以退出。tcpdump中抓取的众多数据包中,只有最靠前的两个和ARP通信有关,将其列出:
第一个数据包,依次看过去,源地址:00:16:d3:5c:b9:e3,目的地址:ff:ff:ff:ff:ff:ff 这是以太网的广播地址,即表示整个LAN,0x0806以太网帧头部类型字段的值 表示ARP模块,长度为42字节;数据部分长度28字节,”Request”表示这是一个ARP请求,”who-has”表示查询对应IP地址。第二个数据包同理
ARP请求和应答实际是从以太网驱动程序发出的,而并非像图中描述的那样从ARP模块直接发送到以太网上,所以用虚线表示。路由器也将接到以太网帧1,因为该帧是一个广播帧。
1.6 DNS工作原理 我们通常使用机器的域名来访问这台机器,而不直接使用IP地址。如何将机器的域名转换成IP地址,这就需要用到域名查询服务。有很多种实现方式,比如NIS **(Network Information Service, 网络信息服务)**,DNS和本地静态文件,本节主要讨论DNS
a) DNS查询和应答报文详解
DNS是一套分布式的域名服务系统。每个DNS服务器上存放着大量的机器名和IP地址的映射,并且动态更新的。众多网络客户端使用DNS协议来向DNS服务器查询目标主机的IP地址。DNS查询和应答报文格式如下
具体字段分析,见p13
b) Linux下访问DNS服务
我们要访问DNS服务,必须先直到DNS服务器的IP地址。Linux使用/etc/resolvconf文件来存放DNS服务器的IP地址,内容如下
Linux下一个常用的访问DNS服务器的客户端程序是host,比如下面的命令是向首选DNS服务器219.239.26.42查询机器www.baidu.com的IP地址:
c) 使用tcpdump观察DNS通信过程
下面将在ernest-laptop上运行host命令,查询,并使用tcpdump抓取这一过程中的LAN上传输的以太网帧。
使用port domain来过滤数据包,表示只抓取使用domain服务的数据包,输出如下:
第一个数据包中,数值57428是DNS查询报文的标识值,因此该值也出现在DNS应答报文中。”+”表示启用递归查询标志,”A?”表示使用A类型的查询方式。”www.baidu.com"则是DNS查询问题中的查询名,括号中的数值31是DNS查询报文的长度
第二个数据包中,”3/4/4”表示该报文中包含3个应答资源记录,4个授权资源记录和4个额外信息记录。”CNAMEwww.baidu.com, A 119.75.218.77, A 119.75.217.56”则表示3个应答资源记录的内容,其中CNAME表示机器别名,A表示的记录是IP地址,长度为226字节
1.7 socket 和 TCP/IP 协议族的关系 数据链路层,网络层,传输层协议是在内核中实现的。因此操作系统需要实现一组系统调用,使得应用程序能够访问这些协议提供的服务。实现这组系统调用的API主要有两套:socket和XTI。本书仅讨论socket。
第2章 IP协议详解 IP协议是TCP/IP的核心协议,也是socket网络编程的基础之一。本章从IP头部信息和IP数据报的路由和转发两个方向深入探讨IP协议。
2.1 IP服务的特点 IP协议是TCP/IP协议族的动力,它为上层协议提供无状态,无连接,不可靠的服务。
无状态是指IP通信双方不同步传输数据的状态信息,因此所有IP数据报的发送,传输和接收都是相互独立,没有上下文关系的。这种的服务的最大缺点是无法处理乱序和重复的IP数据报,优点是简单,高效。
无连接是指IP通信双方都不长久地维持对方的任何信息,每次上层协议发送数据时,都必须明确指定对方的IP地址。
不可靠是指IP协议不能保证IP数据报准确地到达接收端。
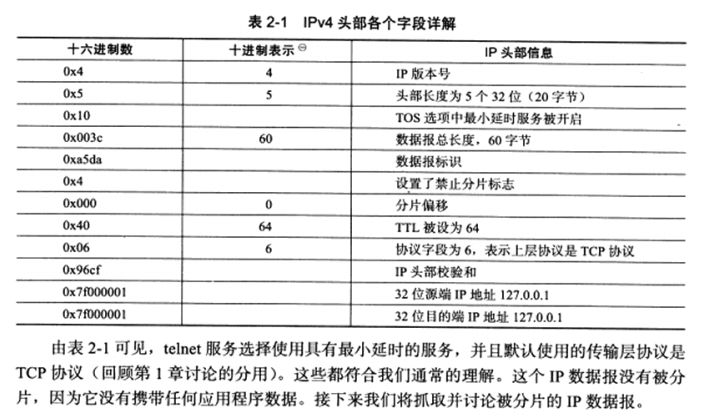
2.2 IPV4头部结构 a) IPV4头部结构
4位版本号指定IP协议的版本,对于IPV4来说是4。其他IPV4协议的扩展版本则有不同版本号。
4位头部长度表示IP头部有多少个32bit字 (4字节) ,4位最大表示15,所以最长60字节
8位服务类型,包括一个3位优先权字段 **(已被忽略)**,4位的TOS字段和1位的保留字段 **(必须置0)**,4位的TOS字段分别表示:最小延时,最大吞吐量,最高可靠性,最小费用。
16位总长度是指整个IP数据报的长度,所以最大65535 **(2^16-1)**,但由于MTU的限制,实际上超过MTU的数据报都将被分片传输。
16位标识唯一地表示主机发送的每一个数据报。其初始值由系统随机生成:每发送一个数据报,其值+1。该值在数据报分片时被复制到每个分片中,因此所有分片拥有相同的标识值。
3位表示字段的第一位保留。第二位DF **(Don’t Fragment)**表示”禁止分片” ,第3位表示MF (More Fragment) “更多分片”。除了数据报的最后一个分片外,其它都要把它置1
13位分片偏移时分片相对原始IP数据报开始处的偏移。
8位生存时间 **(Time To Live, TTL)**,常见的值时64,每经过一个路由,该值减1。为0时,路由器丢弃数据报
8位协议 **(protocol)**用来区分上层协议,类似于TCP的端口,其中ICMP是1,TCP是6,UDP是17。
16位头部校验和,检验IP数据报头部在传输过程中是否损坏。
32位的源端IP地址和目的端IP地址用来表示数据报的发送端和接收端。
IPV4的最后一个字段是可变长的可选信息。最多包含40字节,因为前面部分已经讨论了20字节固定字节,而IP头部最长是60字节。可用的IP选项包括:
记录路由,告诉数据报途径的路由器将IP地址填入头部选项部分,可用来跟踪传递路径。
时间戳,告诉路由器将转发时间填入,测量途径传输的时间。
松散源路由选择,指定一个路由器IP地址列表,数据报必须经过其中的所有路由器。
严格源路由选择,数据报只能经过指定的路由器。
b) 使用tcpdump观察IPV4头部结构
使用测试机器ernest-laptop执行talnet命令登陆本机,使用tcpdump抓取这个过程中交换的数据报。
此时观察tcpdump输出的第一个数据包
由于是本机,所以IP地址是127.0.0.1本地回环。flags,seq,win,options位TCP头部信息,第3章讨论
本次抓包开启了tcpdump的-x选项,使之输出数据报的二进制码,此数据包共60字节,前20字节是IP头部,后40字节是TCP头部,不包含应用程序数据 **(length值为0)**分析结果如下。
2.3 IP分片 当IP数据报的长度超过帧的MTU时,它将被分片传输。分片可能发生在发送端,也可能发生在中转路由器上,而且可能在传输过程中被多次分片,但只有在最终的目标机器上,这些分片才会被内核中的IP模块重新组装。
和分片关系比较紧密的三个字段:数据报标识,标志和片偏移。每个分片都具有相同的标识值,具有不同的片偏移,且除了最后一个分片外,其他分片设置MF标志。此外,每个分片的IP头部的总长度字段将被设置为该分片的长度。
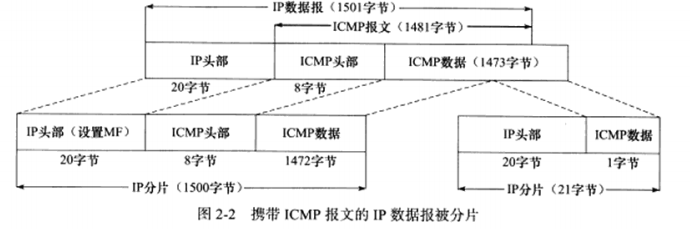
以太网帧的MTU是1500,因此它可携带的IP数据报的数据部分最多是1480字节 **(IP头部占用20字节)**。考虑用IP数据报封装一个1481的ICMP报文(包括8字节的ICMP头部),分片如下图。
分片为两块,都具有自己的IP头部,且第一个分片设置了MF标志,但ICMP头部只有第一个分片有,因为IP模块重组该ICMP报文的时候只需要一份ICMP头部信息。
ICMP报文的头部长度取决于报文的类型,其变化范围很大。图中8字节原因是后面的例子用到了ping程序,而ping程序使用的ICMP回显和应答报文的头部类型是8字节。
考虑从ernest-laptop来ping机器kongming20,每次发送1473字节来强制引起分片,并使用tcpdump来抓取数据包,操作如下:
tcpdump输出的两个分片,内容如下:
可以看出它们具有相同的标识值 61197,说明是同一个IP数据报的分片。flags [+] 说明设置了MF标志,而第二个分片不设置。片偏移不同。
2.4 IP路由 IP协议的一个核心任务是数据报的路由,即发送数据报到目标机器的路径。
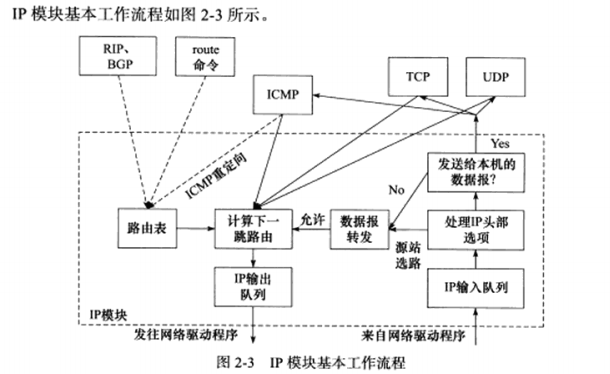
a) IP模块工作流程
当IP模块接收到来自数据链路层的IP数据报时,它首先对该数据报的头部做CRC校验,确认无误后就分析其头部的具体信息 。
如果该IP数据报的头部设置了源站选路选项 (松散源路由选择或严格源路由选择),则IP模块调用 数据报转发子模块 来处理该数据报。如果IP数据报的头部中目的IP地址是本机 的某个IP地址,或者是广播地址,则IP模块根据数据报头部中的协议字段来决定将他派发给上层应用 。如果不是发送给本机的,也交给数据报转发子模块 。
数据报转发子模块 首先检测系统是否允许转发,如果不允许,IP模块将数据报丢弃。如果允许,对该数据执行一些操作,然后将他交给IP数据报输出子模块
IP数据报应该发送至哪一个吓一跳路由,以及经过哪个网卡来发送,就是 IP路由过程 ,即图2-3中的计算下一条路由子模块 。IP模块实现数据报路由的核心数据结构是路由表。
IP输出队列中存放的是所有等待发送的IP数据报,其中除了需要转发的IP数据报外,还包括封装了本机上层数据的IP数据报。
图2-3中的虚线箭头显示了路由表更新过程。
b) 路由机制
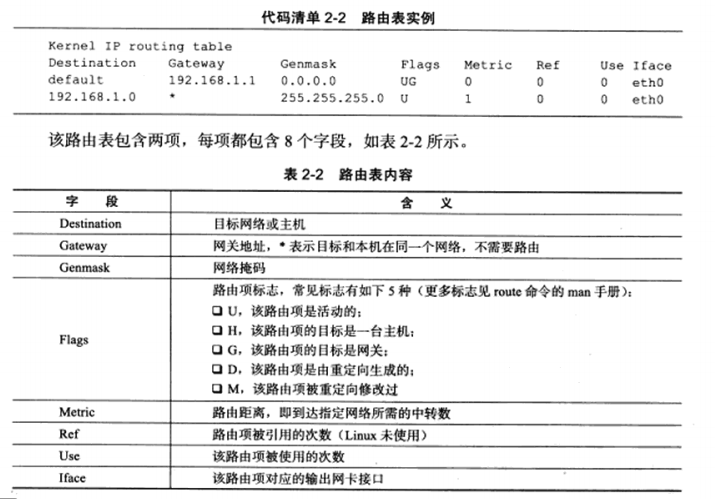
使用route命令或netstat命令查看路由表,测试机器上执行route内容如下:
路由表如何按照IP地址分类?或者说给定数据报的目标IP地址,它将匹配路由表中的哪一项呢?这就是IP的路由机制,分为3个步骤:
查找路由表中和数据报的目标IP地址完全匹配的主机IP地址。如果找到,就使用该路由项,没找到则转步骤2
查找路由表中和数据报的目标IP地址具有相同网路ID的网络IP地址(比如代码清单2-2所示的路由表中的第二项)。如果找到,就使用该路由项:没找到则转步骤3
选择默认路由,这通常意味着数据报的吓一跳路由是网关。
因此,对于测试机器ernest-laptop而言,所有发送到IP地址为192.168.1.*的机器的IP数据报都可以直接发送到目标机器(匹配路由表第二项),而所有访问因特网的请求都通过网关来转发(匹配默认路由项)。
c) 路由表更新
路由表必须能够更新,以反映网络连接的变化,这样IP模块才能够准确,高效地转发数据报。route命令可以修改路由表,如下:
第1行标识添加主机192.168.1.109(机器Kongming20)对应的路由项。这样设置之后,所有从ernest-laptop发送到Kongming20的IP数据报将通过网卡eth0直接发送到目标机器的接收网卡。第2行标识删除网络192.168.1.0对应的路由项,这样除了机器Kongming20外,测试机器无法访问局域网上的任何其他机器。第3行标识删除默认路由项,这样做的后果是无法访问因特网。第4行标识重新设置默认路由项,不过这次其网关是机器Kongming20,修改后的路由表内容如下:
第一个路由项是主机路由项,所以它被设置了”H”标志。设计该路由表的目的是为后文讨论ICMP重定向提供环境。
2.5 IP转发 前文提到,不是发送给本机的IP数据报都将由数据报转发子模块来处理。路由器能执行数据报的转发操作,而主机一般只发送和接收数据报,这是因为主机上/proc/sys/net/ipv4/ip_forward内核参数默认被设置为0。我们可以修改它来使能主机的数据报转发功能:
对于允许IP数据报转发的系统,数据报转发子模块将对期望转发的数据报执行如下操作:
检测数据报头部的TTL值,为0则丢弃。
查看数据报头部的严格选路由选择选项。如果设置,则检测数据报的目标IP地址是否是本机的某个IP地址。如果不是,则发送一个ICMP源站选路失败报文给发送端。
如果有必要,则给源端发送一个ICMP重定向报文,以告诉他更合理的吓一跳。
将TTL值减1
处理IP头部选项
如有必要,执行分片
2.6 重定向 图2-3显示了ICMP重定向报文也能用于更新路由表,简要讨论ICMP重定向
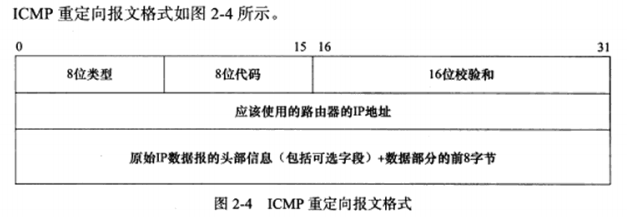
a) ICMP重定向报文
ICMP重定向报文的类型值是5,代码字段有4个可选值,用来区分不同的重定向类型。本届仅讨论主机重定向,代码值为1
数据部分为接收方提供如下两个信息:
引起重定向的IP数据报的源端IP地址
应该使用的路由器IP地址
接收主机以此来选择应该使用的路由器,并且更新路由表
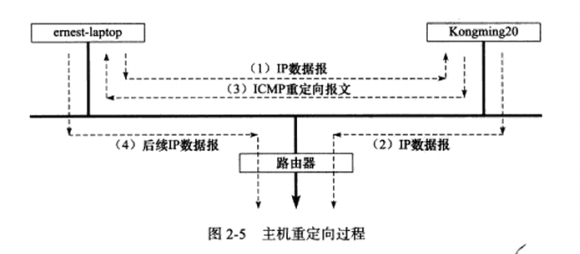
b) 主机重定向示例
2.4.3中将机器ernest-laptop的网关设置成了机器Kongming20,2.5节又使能了Kongming20的数据报转发功能,因此机器ernest-laptop将通过Kongming20来访问因特网,如在ernest-laptop上执行ping命令:
Kongming20给ernest-laptop发送了一个ICMP重定向报文,告诉它通过192.168.1.1来访问目标机器,因为这对ernest-laptop来说是更合理的路由方式。主机ernest-laptop收到这样的ICMP重定向报文后,更新路由表缓冲,并使用新的路由方式来发送后续数据报
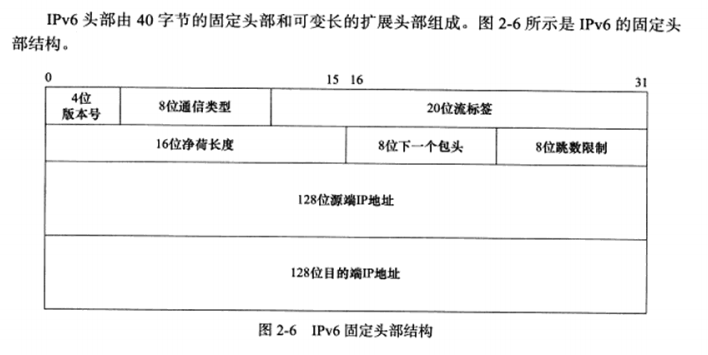
2.7 IPV6头部结构 简要讨论IPV6头部结构
a) IPV6固定头部结构
b)IPV6扩展头部
可变长的扩展头部使得IPV6可以支持更多选项,并且很便于将来的扩展需求。
第3章 TCP协议详解 本章主要从四个方面来讨论TCP协议:
TCP头部信息
TCP状态转移过程
TCP数据流
TCP数据流的控制
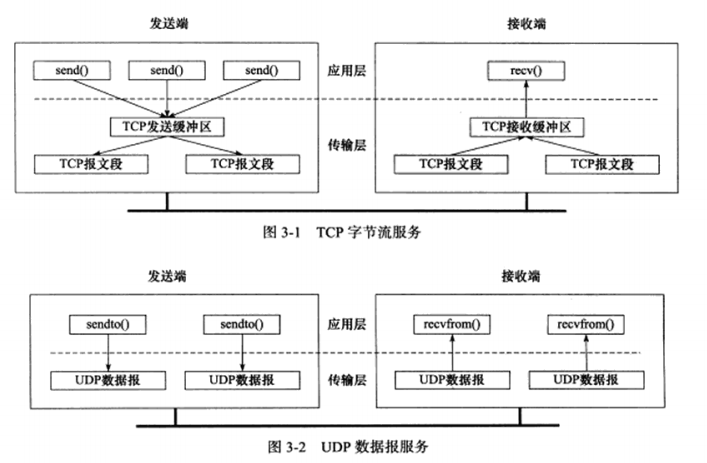
3.1 TCP服务的特点 TCP协议相对于UDP协议的特点是:面向连接,字节流和可靠传输。
TCP协议的连接是一对一的,所以基于广播和多播的应用程序,不能使用TCP服务。而无连接协议UDP非常适合广播和多播。
字节流指应用程序执行读操作次数和TCP模块接收到的TCP报文段之间没有固定的数量关系,由接收端/发送端,先接收/写到TCP发送/接收缓冲区,再由应用程序读写;与之不同的UDP则是数据报服务,发送端应用程序每执行一次写操作,UDP模块就将其封装成一个UDP数据报并发送只。
可靠,TCP协议采用发送应答机制,每个TCP报文段必须得到接收方的应答,才认为这个TCP报文传输成功。且TCP协议采用超时重传机制。以及对收到的可能乱序,重复的IP数据报,重排,整理,再交付应用层。
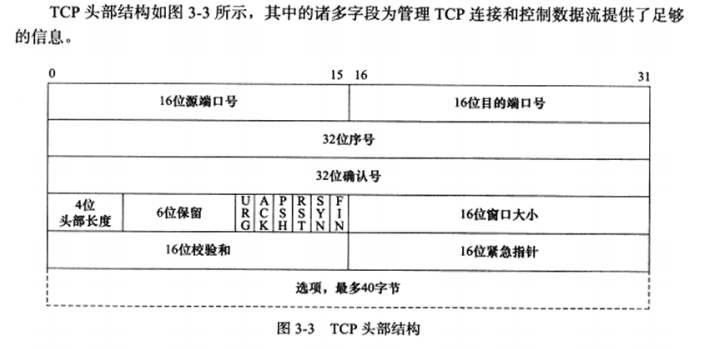
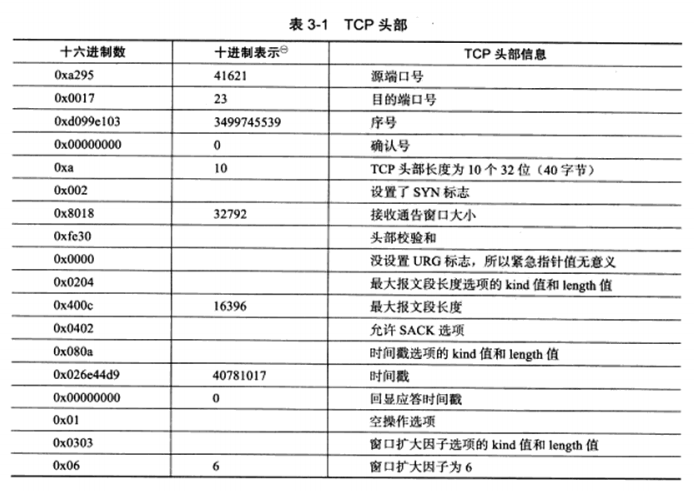
3.2 TCP头部结构 TCP头部信息出现在每个TCP报文段中。本节详细介绍
a) TCP固定头部结构
16位端口号:告知该报文段来自哪里以及传给哪个上层协议或应用程序。
32位序号:一次TCP通信过程中某一个传输方向上的字节流的每个字节的编号。
32位确认号:用作对另一方发送来的TCP报文段的响应。其值是收到的TCP报文段的序号值+1。
4位头部长度:标识该TCP头部有多少个32bit字(4字节)。4位最大表示15,所以TCP头部最长60字节。
6位标志位包含如下几项:
URG标志:表示紧急指针是否有效
ACK标志:表示确认号是否有效,携带ACK标志的TCP报文段为确认报文段。
PSH标志:提示接收端应用程序立即从TCP接收缓冲区中读走数据,为接收后续数据腾出空间。
RST标志:表示要求对方重新建立连接,携带RST为复位报文段
SYN标志:表示请求建立一个连接,携带SYN为同步报文段。
FIN标志:表示通知对方本端要关闭连接了,携带FIN为结束报文段。
16位窗口大小:TCP流量控制的一个手段。
16位校验和:接收端执行CRC算法以检验TCP报文段在传输过程中是否损坏。
16位紧急指针:是一个正的偏移量。它和序号字段的值相加表示最后一个紧急数据的下一字节的序号。
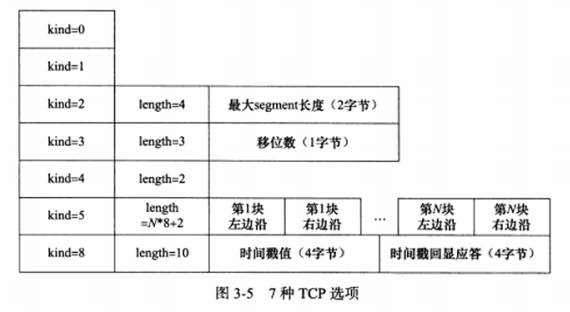
b) TCP头部选项
TCP头部的最后一个选项是可变长的可选信息。这部分最多40字节,因为TCP最长60,前面固定已占了20字节。典型的TCP头部选项结构如下:
kind说明选项的类型,有的TCP选项没有后面的两个值,length指定该选项的长度,包括kind和length占据的2字节,info是选项的具体信息。常见的有7种,如下:
kind0:选项表结束选项。
kind1:空操作(nop)选项,没有特殊含义,一般用于将TCP选项的总长度填充为4字节的整数倍。
kind2:最大报文段长度选项。通信双方使用该选项来协商最大报文段长度(MSS)。通常设置为(MTU-40)字节,减掉的包括20字节IP头部和20字节TCP头部,避免IP分片。
kind3:窗口扩大因子选项。TCP头部种,接收通过窗口大小是用6位表示的(即65535),但TCP模块允许的大小远不止这个数,通过该选项可以扩大该值,如假设TCP头部中的接收通告窗口大小是N,扩大因子是M,即将N左移M位。
kind4:选择性确认选项。若通信时某个TCP报文段丢失,TCP模块会重传最后被确认的TCP报文段后续的所有报文段,这样会导致原先已经正确传输的TCP报文段被重复发送,从而降低TCP性能。该选项使TCP模块只重新发送丢失的TCP报文段。
kind5:是选择性确认(Selective Acknowledgment, SACK)实际工作的选项。
kind8:时间戳选项。该选项提供了较为准确的计算通信双方之间的回路时间(RTT)的方法。
c) 使用tcpdump观察TCP头部信息
抓取的TCP报文段如下:
Flags[S]:表示包含SYN标志,因此他是一个同步报文段。
seq:序号值,因为这是该方向上第一个TCP报文段,所以这个序号值也就是本次通信该方向上的ISN(Initial Sequence Number, 初始序号值)。
win:接收通告窗口的大小。
options:tcp选项,mss为最大报文长度。通过ifconfig查看mtu为16436,所以mss为MUT-40,16396。sackOK表示同意使用SACK选项,TSval是发送端的时间戳,ecr是时间戳回显应答。nop是一个空操作,wscale指出发送端的扩大银子为6.
字节码即,TCP头部中对应的消息:
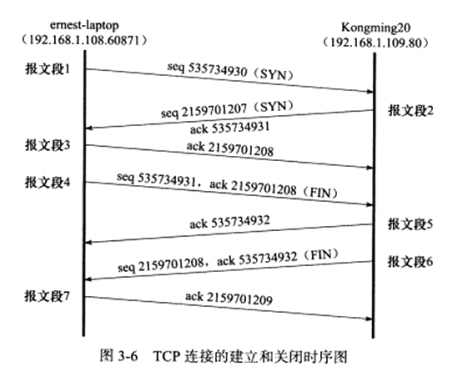
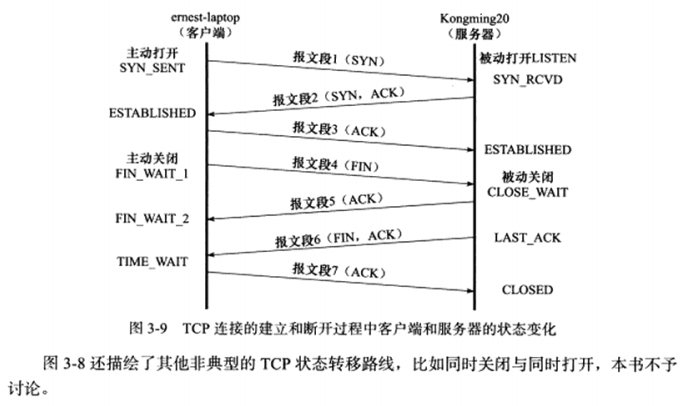
3.3 TCP连接的建立和关闭 a) 使用tcpdump观察TCP连接的建立和关闭
可以看出是三次握手建立连接,以及四次握手关闭连接
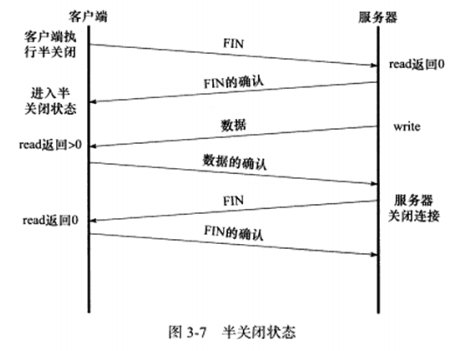
b) 半关闭状态
TCP连接是全双工的,所以它允许两个方向的数据传输被独立关闭。也就是允许一端发送结束报文,告诉对端本端已完成数据的发送,但允许继续接收来自对端的数据,直到对方也发送结束报文。
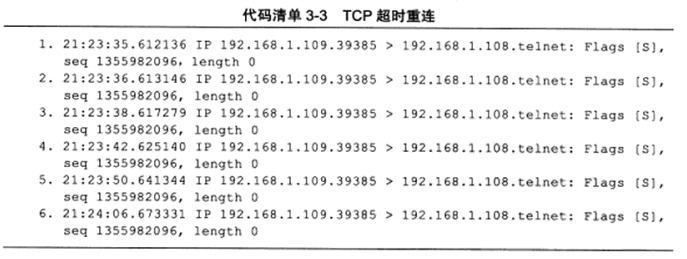
c) 连接超时
这里采用iptable命令过于数据包,丢弃它所接收到的连接请求。随后用tcpdump抓取。
可以看出在5次重连均失败的情况下,TCP模块放弃连接并通知应用程序。
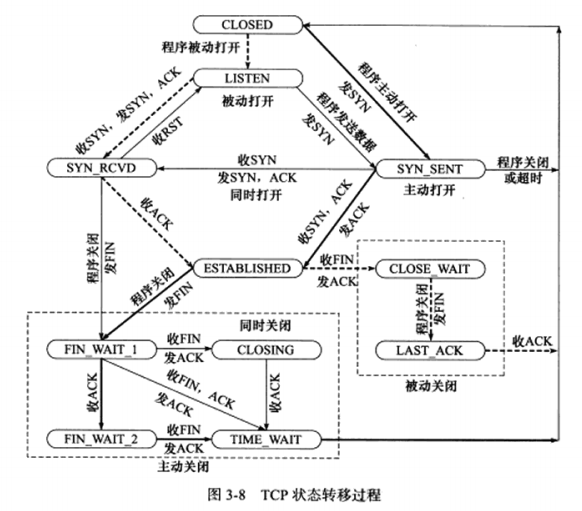
3.4 TCP状态转移 下图是完整的状态转移图,可以通过netstat命令查看TCP连接处于何种状态。
粗实线表示典型的客户端连接的状态转移,虚线可以看作服务端收到客户端的连接请求后的状态转移,CLOSED为一个假象状态,实际并不存在。
a) TCP状态转移总图
先讨论服务器典型的状态转移。
服务端listen调用进入LISTEN状态,接收到SYN,将连接放入内核等待队列,并向对端发送带SYN标志的ack确认报文段,此时处于SYN_RCVD状态。接收到对端回发的确认报文段后,转移到ESTABLISHED状态。
收到结束报文段,并返回确认报文段后,进入CLOSE_WATI状态,随后等待服务器应用程序关闭连接,发送一个结束报文段后进入LASK_ACK状态,在此等待最后一个确认,一旦确认即彻底关闭。
客户端同意,但注意一个TIME_WATI状态,后续讨论。
b) TIME_WATI状态
客户端在收到服务端的FIN后,没有立即进入CLOSED状态,而要等待一段长为2MSL(报文段最大生存时间)的时间,大概是2分钟,该状态存在的两点原因:
可靠地终止TCP连接
保证让迟来的TCP报文段有足够的时间被识别并丢弃
通过setsockopt选项SO_REUSEADDR设置端口复用,可以避免TIME_WAIT状态连接占用的端口。
3.5 复位报文段 本节讨论产生复位报文段的三种情况
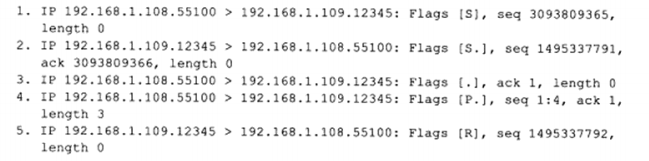
a) 访问不存在的端口
如以下命令访问一个不存在的54321端口:
抓取的TCP报文段如下:
以及对于仍处于TIME_WATI的端口发起连接,客户端程序也将收到复位报文段。
b) 异常终止连接
前面讨论的连接终止方式都是正常的种植方式:数据交换完成后,通过结束报文段。TCP提供了异常终止的一个连接方式,即给对方发送一个复位报文段。一旦发送了复位报文段,发送端所有排队等待发送的数据都被丢弃。通过使用socket选项的SO_LINGER来发送复位报文段,以异常终止一个连接。
c) 处理半打开连接
如下情况,服务器关闭或异常终止了连接,而对方没有收到结束报文段,此时客户端还维持着原来的连接。如果此时客户端向半打开状态的连接写入数据,对方将回应一个结束报文段。
如执行如下命令:
tcpdump抓取的TCP报文段如下:
前3个报文段为TCP3次握手的建立,第4个报文段为客户端发送给服务器携带应用程序数据的报文段,length3,为”a”, 回车符\r , 换行符\n。
3.6 TCP交互数据流 TCP报文段锁携带的应用程序数据按照长度分为两种:交互数据和成块数据。交互数据仅包含很少的字节。对实时性要求高的应用程序一般采用该种,如telnet,ssh。成块数据长度通常为TCP报文段允许的最大数据长度,对传输效率高的应用程序采用这种如ftp。
执行如下命令:
tcpdump抓取的TCP报文段如下:
3.7 TCP成块数据流 下面考虑FTP协议传输一个大文件。命令如下:
tcpdump输出如下:
前面16个报文段都为,服务端向客户端发送数据,17,18则是客户端对于TCP报文段2和16的确认。由此可见,当传输大量大块数据的时候,发送方会连续发送多个TCP报文段。
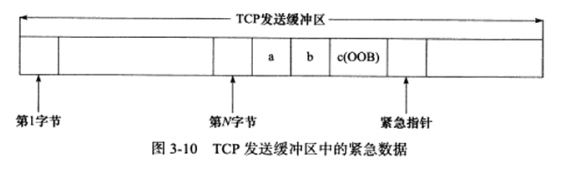
3.8 带外数据 有些传输层协议具有带外数据的概念,用于迅速通告对方本端发生的重要事件。因此,带外数据比普通数据有更高的优先级,它应该总是立即被发送,而不论发送缓冲区种是否有排队等候发送的普通数据。
UDP没有实现带外数据,TCP也米有真正的带外数据。不过TCP利用其头部种的紧急指针标志和紧急指针字段,给应用程序提供了一种紧急方式。
具体过程如下,假设一个进程已经往某个TCP连接的发送缓冲区种写入了N字节的普通数据。在数据被发送前,该进程又向这个连接写入了3字节的带外数据”abc”。此时,待发送的TCP报文段将被设置URG标志,并且紧急指针被设置为指向最后一个带外数据的下一字节。
3.9 TCP超时重传 TCP服务必须能够重传超时时间内未收到确认的TCP报文段。为此,TCP模块为每个TCP报文段都维持一个重传定时器,该定时器在TCP报文段第一次被发送时启动。如果超时时间内未收到接收方的应答,TCP模块将重传TCP报文段并重置定时器。至于下次重传的超时时间如何选择,以及最多执行多少次的重传,就是TCP的重传策略,通过示例来研究。
执行如下命令:
tcpdumo抓取的TCP报文段如下:
前3次为三次握手建立连接,4和5为1234数据的发送和应答,后续执行了5次重传,均失败的情况下,底层的IP和ARP开始接管,直到telnet客户端放弃连接为止。
虽然超时会导致TCP报文段重传,但TCP报文段的重传可以发生在超时之前,即快速重传。
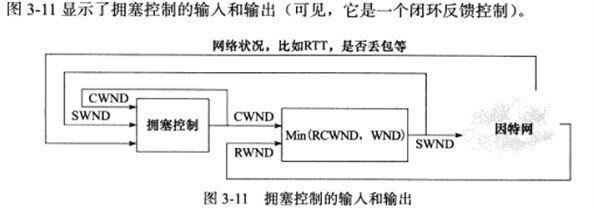
3.10 拥塞控制 a) 拥塞控制概述
TCP模块还有一个重要的任务,就是提高网络利用率,降低丢包率,并保证网络资源对每条数据流的公平性,这就是所谓的拥塞控制。
拥塞控制的四个部分:慢启动,拥塞避免,快速重传 和 快速恢复。
拥塞控制的最终受控变量是发送端向网络一次连续写入的数据量,我们称为SWND(Send Window, 发送窗口)。不过,发送端最终以TCP报文段来发送数据,所以SWND限定了发送端能连续发送的TCP报文段数量。
发送端需要合理的选择SWND的大小,如果SWND太小,会引起明显的网络延迟;反之,如果太大,则容易导致网络拥塞。接收方可以通过其接收通过窗口(RWND)来控制发送端的SWND,但这不够,所以发送端引入了一个称为拥塞窗口(Congestion Winod, CWND)的状态变量。实际的值是RWND和CWND种的较小值。
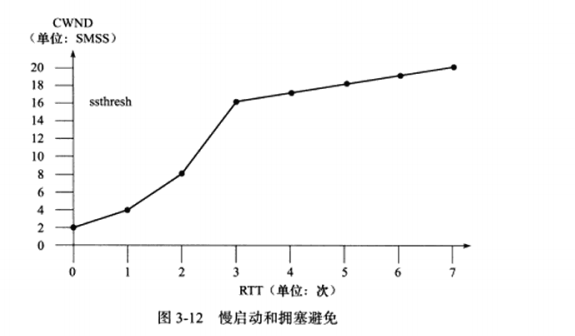
b) 慢启动和拥塞避免
TCP连接建立好后,CWND将被设置成初始值IW(Initial Window),其大小为2~4个SMSS(Sender Maximum Segment Site,发送者最大段大小)。此时发送端最多能发送IW字节的数据。此后发送端每收到接收端的一个确认,其CWND就按照式(3-1)增加:
其中N是此次确认中包含的之前未被确认的字节数。这样一来,CWND将按照指数形式扩大,这就是所谓的慢启动。该算法的理由是,TCP模块一开始不知道网络的实际情况,通过一个试探的方式平滑的增加CWDN的大小。
但如果不施加其他手段,慢启动必然使得CWND膨胀,导致网络阻塞。因此TCP拥塞控制中定义了另一个重要的状态变量:慢启动门限(ssthresh) 。当CWND的大小超过该值时,TCP拥塞控制将进入拥塞避免阶段。
拥塞避免算法使得CWND按线性方式增加,从而减缓其扩大。两种实现方式:
每个RTT时间内按照(3-1)计算新的CWND,而不论该RTT时间内发送端接收到多少个确认。
没收到一个对新数据报的确认报文段,按(3-2)来更新CWND
如果给出一张图示,如下:
以上为发送端在未检测到拥塞时所采用的积极避免拥塞的方法。接下来介绍拥塞发生时拥塞控制行为。首先搞清除发送端如何判断拥塞已经发生,依据有两个:
传输超时,或者说TCP重传定时器溢出
接收到重复的确认报文段
拥塞控制对这两种情况有不同的处理方式,对第一种情况仍然使用慢启动和拥塞避免。对第二种情况则使用快速重传和而快速恢复,这种情况随后讨论。注意如果第二种情况发生在重传定时器溢出之后,则也被拥塞控制当成第一种情况来对待。
如果发送端检测到拥塞发生是由于传输超时,即第一种情况,将执行重传并做如下调整:
其中FlightSize是已经发送但未接收到确认的字节数,这样调整之后,CWND将一定小于SMSS,那么也必然小于新的慢启动门限ssthresh,故而拥塞控制再次进入慢启动阶段。
c) 快速重传和快速恢复
在很多情况下,发送端都可能收到重复的确认报文段。如TCP报文段丢失,或者接收端收到乱序TCP报文段并重排之等。拥塞控制算法首先需要判断网络是否真的发生了阻塞。具体做法是:如果连续收到3个重复的确认报文段,就认为是拥塞发生了。然后它启用快速重传和快速恢复算法来处理拥塞,过程如下:
1.收到3个重复确认报文段时,按式(3-3)计算ssthresh,然后立即重传丢失的报文段,并按照式(3-4)设置CWND
2.每次收到1个重复的确认时,设置CWND = CWND + SMSS。此时发送端可以发送新的TCP报文段,如果CWND允许的话。
3.当收到新的数据的确认时,设置CWND = ssthresh 该慢启动门限为新的,由第一步设置
快速重传和快速恢复完成后,拥塞控制将恢复到拥塞避免阶段。
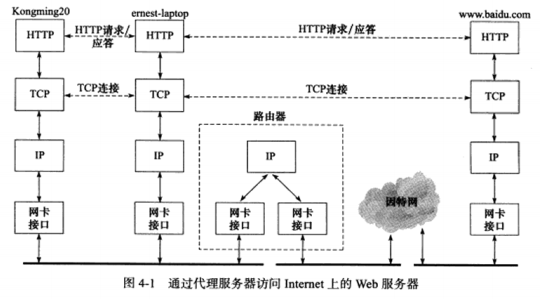
第4章 TCP/IP通信案例:访问Internet上的Web服务器 4.1 示例总图 在Kongming20上运行wget客户端,在ernest-laptop运行squid代理服务器程序。客户端通过代理服务器的中专,获取Internet上的主机www.baidu.com的首页文档index.html
为了将ernest-laptop设置为Kongming20的HTTP代理服务器,需要在Kongming20上设置环境变量http_proxy:
1 $ export http_proxy="ernest-laptop:3128"
3128为squid服务器默认使用的端口号。
4.2 部署代理服务器 简单介绍代理服务器的工作原理以及如何部署。
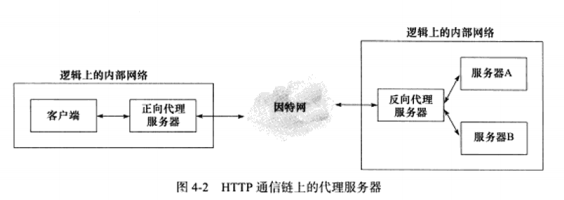
a) HTTP代理服务器的工作原理
HTTP通信链上,客户端和目标服务器之间通常存在某些中转代理服务器,它们提供对目标资源的中转访问。代理服务器按照其使用方式和作用,分为正向代理服务器,反向代理服务器和透明代理服务器。
正向代理:要求客户端自己设置代理服务器的地址。客户每次的请求都直接发送到该代理服务器,并由代理服务器来请求目标资源。
反向代理:反向代理被设置在服务器端,因此客户端无须进行任何设置。方向代理用代理服务器来接收internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从内部服务器上得来的结果返回给客户端。
透明代理:只能设置在网关上。透明代理可以看作正向代理的一种特殊情况。
b) 部署squid代理服务器
在ernest-laptop上部署squid代理服务器。只需修改服务器的配置文件/etc/squid3/suiqd.conf,在其加入如下两行代码(需要root权限,应加在合适的为止,详细参考其他类似条目的设置):
1 2 acl localnet src 192.168 .1 .0 /24 http_access allow localnet
192.168.1.0/24是CIDR(Classless Inter-Domain Routing,无类域间路由)风格的IP地址表示方法。
接下来在ernest-laptop上执行如下命令,以重启squid服务器:
1 2 $ sudo service squid3 restart *Restarting Squid HTTP Proxy 3.0 squid3 [ok]
service是一个脚本程序,为/etc/init.d/目录下的众多服务器程序的启动,停止等动作提供了一个统一的管理。
4.3 使用tcpdump抓取传输的数据包 执行wget命令前,首先删除ernest-laptop的ARP高速缓存,以便观察TCP/IP通信过程中ARP协议何时起作用,完整操作如下:
一共抓取了43个数据包,按照逻辑关系分为如下四部分:
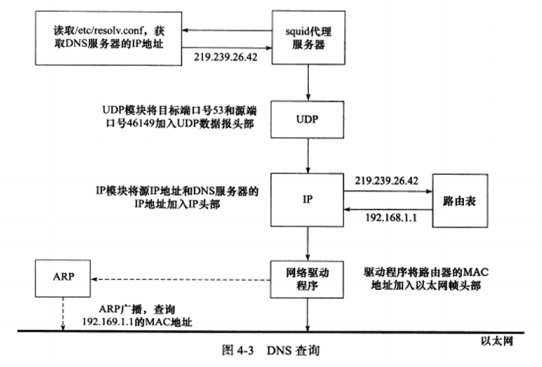
代理服务器访问DNS服务器查询域名www.baidu.com对应的IP地址,数据包8,9。
代理服务器查询路由器MAC地址的ARP请求和应答,数据包6,7。
wget客户端(192.168.1.109)和代理服务器(192.168.1.108)之间的HTTP通信,数据包15,2325,32~40,42,43。
代理服务器和Web服务器(119.75.218.77)之间的HTTP通信,数据包1022,2631,41。
4.4 访问DNS服务器 数据包8,9表示代理服务器向DNS服务器查询域名www.baidu.com对应的IP地址,得到回应。回复包括一个主机别名和两个IP地址。
完整过程如下图:
4.5 本地名称查询 通过域名来访问internet上的某台主机时,需要使用DNS服务来获取该主机的IP地址。但如果通过主机名来访问本地局域网上的机器,则可通过本地的静态文件来获得该机器的IP地址。
Linux将目标主机及其对应IP地址存储在/etc/hosts配置文件中。如Kongming20上/etc/hosts文件的内容如下:
1 2 3 127.0 .0 .1 localhost192.168 .1 .109 Kongming20192.168 .1 .108 ernest-laptop
程序在/etc/hosts文件中未找到目标机器名对应的IP地址,它将求助于DNS服务。
用户可以通过修改/etc/host.conf文件来自定义系统解析主机名的方法和顺序。
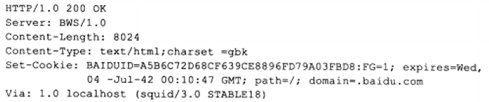
4.6 HTTP通信
本例的过程中,客户端仅给服务器发送了一个HTTP请求,即TCP报文段4,请求的长度为136字节。代理用6个TCP报文段(23,24,25,33,35,36)给客户端返回了总长度为8522字节的HTTP应答。客户端使用7个TCP报文段(32,34,37,38,39,40,42)来确定这8552字节的HTTP应答数据。
a) HTTP请求
请求的部分内容如下:
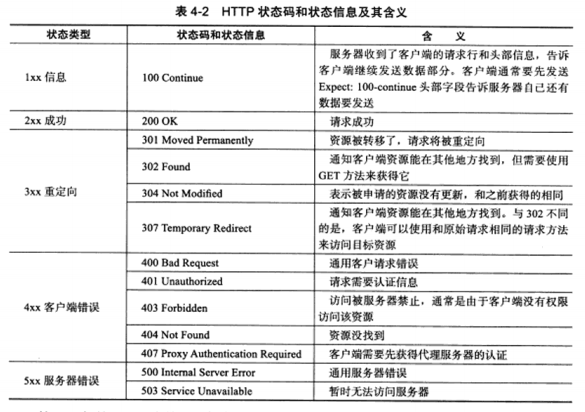
GET为请求方法,一共有如下9种:
http://www/baidu/com/index.html 是目标资源的URL,”http”是所谓的scheme,表示获取目标资源所需使用的应用层协议。www.baidu.com是目标主机,index.html是指定资源文件名称
HTTP/1.0表示客户端使用的HTTP版本号是1.0。
User-Agent表示客户端使用的程序。
Host表示目标主机名。
Conection表示如何处理连接方式。
b) HTTP应答
第一行是状态行,HTTP/1.0表示服务器使用的协议版本号,通常需要和客户端一致。
往下分别是,服务器程序名,目标内容的长度,目标内容的MIME类型,以及cookie。
via表示HTTP应答在返回过程中经历的所有代理服务器的地址和名称。
第5章 Linux网络编程基础API 5.1 socket地址API a) 主机字节序和网络字节序
不同规定导致的字节沿地址增长方向不同,高位存储在低地址为大端字节序,高位存储在高地址,则为小端。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <stdio.h> void byteorder () { uninon { short value; char union_bytes[sizeof (short )]; } test; test.value = 0x0102 ; if ((test.union_bytes[0 ] == 1 ) && (test.union_bytes[1 ] == 2 )) { printf ("big endian\n" ); } else if ((test.union_bytes[0 ] == 2 ) && (test.union_bytes[1 ] == 1 )) { printf ("little endian\n" ); } else { printf ("unkonwn...\n" ); } }
Linux提供了如下4个函数来完成主机字节序和网络字节序之间的转换
1 2 3 4 5 #include <netinet/in.h> unsigned long in htonl (unsigned long int hostlong) ;unsigned short int htons (unsigned short int hostshort) ;unsigned long in ntohl (unsigned long int netlong) ;unsigned short int ntohs (unsigned short int netshort) ;
b) 通用socket地址
socket网络编程中表示socket地址的结构体如下:
1 2 3 4 5 #include <bits/socket.h> struct sockaddr { sa_family_t sa_family; char sa_data[14 ]; }
由于14字节的sa_data无法容纳众多数的协议族的地址值。下面为新的通用地址
1 2 3 4 5 6 #include <bits/socket.h> struct sockaddr_storage { sa_family_t sa_family; unsigned long int __ss_align; char __ss_padding[128 -sizeof (__s_align)]; }
且该结构是内存对齐的
c) 专用socket地址
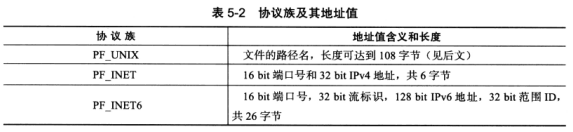
UNIX本地域协议族使用如下专用socket地址结构体:
1 2 3 4 5 #include <sys/un.h> struct sockaddr_un { sa_family_t sin_family; char sun_path[108 ]; }
TCP/IP,分为IPV4的和IPV6的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct sockaddr_in { sa_family_t sin_family; u_int16_t sin_port; struct in_addr sin_addr ; }; struct in_addr { u_int32_t s_addr; }; struct sockaddr_in6 { sa_family_t sin6_family; u_int16_t sin6_port; u_int32_t sin6_flowinfo; struct in6_addr sin6_addr ; u_int32_t sin6_scope_id; }; struct in6_addr { unsigned char sa_addr[16 ]; };
d) IP地址专函函数
下面3个函数可用于点分十进制字符串到网络字节序整数之间的转换:
1 2 3 4 5 6 7 8 9 10 11 12 13 #include <arpa/inet.h> in_addr_t inet_addr (const char * strptr) ;int inet_aton (const char * cp, struct in_addr * inp) ;char * inet_ntoa (struct in_addr in) ;char * szValue1 = inet_ntoa("1.2.3.4" );char * szValue2 = inet_ntoa("10.194.71.60" );printf ("address 1: %s\n" , szValue1);printf ("address 2: %s\n" , szValue2); address1: 10.194 .71 .60 address1: 10.194 .71 .60
下面这对更新的函数也能完成和前面3个函数同样的功能,并且同时适用于IPV4和IPV6
1 2 3 4 5 6 7 8 #include <arpa/inet.h> int inet_pton (int af, const char *src, void *dst) ;const char *inet_ntop (int af, const void *src, char *dst, socklen_t cnt) ;#include <netinet/in.h> #define INET_ADDRSTRLEN 16 #define INET6_ADDRSTRLEN 46
5.2 创建socket 1 2 3 #include <sys/socket.h> #include <sys/types.h> int socket (int domain, int type, int protocol) ;
domain参数指明使用哪个底层协议,如AF_INET,AF_INET6,AF_UNIX。
type参数指定服务类型。主要为SOCKET_STREAM(流服务)适用于TCP协议,SOCK_DGRAM(数据报服务)适用于UDP协议。
protocol在前两个参数的前提下,指定一个具体的协议。因为前两个参数基本已经完全决定了它的值。在几乎所有情况下,把它设置为0,表示默认协议。
5.3 命名socket 即将sockaddr绑到socket上去:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int bind (int sockfd, const struct sockaddr *my_addr, socklen_t addrlen) ;
常见的两种errno
EACCES:被保定的地址是受保护的地址,仅超级用户能访问。
EADDRINUSE:被绑定地址正在使用中。比如绑到一个处于TIME_WAIT状态的socket地址。
5.4 监听socket 创建监听队列存放待处理的客户连接:
1 2 #include <sys/socket.h> int listen (int sockfd, int backlog) ;
backlog参数在内核版本2.2之后,表示完全处于连接状态的socket上线,处于半连接状态的socket上线由 /proc/sys/ipv4/tcp_mas_syn_bakclog内核参数定义。
5.5 接受连接 下面的系统调用从listen监听队列中接受一个连接:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int accept (int sockfd, struct sockaddr *addr, socklen_t addrlen) ;
accept成功时返回一个新的连接socket,该socket唯一地标识了被接收的这个连接。
5.6 发起连接 客户端通过如下系统调用来主动与服务器建立连接:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int connect (int sockfd, const struct sockaddr *serv_addr, socklen_t addrlen) ;
失败常见的两种errno:
ECONNREFUED:目标端口不存在,连接被拒绝。
ETIMEDOUT:连接超时。
5.7 关闭连接 关闭连接,也就是关闭对应的socket,通过如下系统调用:
1 2 #include <unistd.h> int close (int fd) ;
close实际上的操作,是将文件描述符fd的引用计数减1,只有引用计数为0时,才真正关闭连接。所以在多进程程序中,一次fork调用会导致父进程中打开的socket引用计数加1,只有父子进程都执行了close,才能将连接关闭。
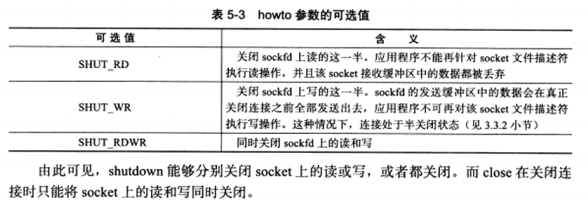
如果想立即终止连接,可以使用shutdown系统调用:
1 2 #include <sys/socket.h> int shutdown (int sockfd, int howto) ;
howto参数决定shutdown的行为:
5.8 数据读写 a) TCP数据读写
socket编程接口提供的几个用于TCP流数读写的系统调用:
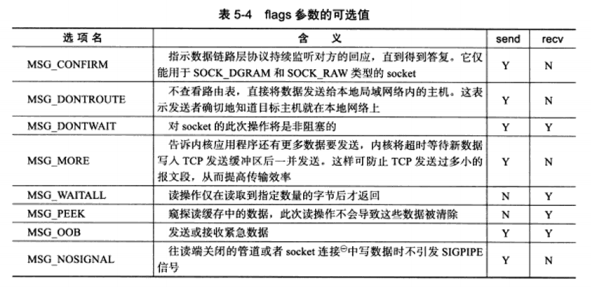
1 2 3 4 #include <sys/types.h> #include <sys/socket.h> ssize_t recv (int sockfd, void *buf, size_t len, int flags) ;ssize_t send (int sockfd, const void *buf, size_t len, int flags) ;
flags参数为数据收发提供了额外的控制,具体可选值如下表:
MSG_OBB选项给应用程序提供了发送和接收带外数据方法,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <string.h> #include <stdlib.h> int main (int argc, char *argv[]) { if (argc <=2 ) { printf ("usage: %s ip_address port_number\n" , basename( argv[0 ]) ); return 1 ; } const char *ip = argv[1 ]; int port = atoi( argv[2 ] ); struct sockaddr_in serv_address ; bzero( &serv_address, sizeof (serv_address) ); serv_address.sin_family = AF_INET; inet_pton(AF_INET, ip, &serv_address.sin_addr ); serv_address.sin_port = htons(port); int sockfd = socket(AF_INET ,SOCK_STREAM, 0 ); assert(sockfd >= 0 ); if (connect(sockfd, (struct sockaddr*)&serv_address, sizeof (serv_address)) < 0 ) { printf ("connection failed\n" ); } else { const char * obb_data = "abc" ; const char * normal_data = "123" ; send(sockfd, normal_data, strlen (normal_data), 0 ); send(sockfd, obb_data, strlen (obb_data), MSG_OBB); send(sockfd, normal_data, strlen (normal_data), 0 ); } close(sockfd); return 0 ; } #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <string.h> #include <stdlib.h> #include <errno.h> #define BUF_SIZE 1024 int main (int argc, char *argv[]) { if ( argc <= 2 ) { printf (...); return 1 ; } const char *ip = argv[1 ]; int port = atoi( argv[2 ] ); struct sockaddr_int address ; bzero( &address, sizeog(address) ); address.sin_family = AF_INET; inet_pton( AF_INET, ip, &address.sin_addr ); address.sin_port = htons( port ); int sock = socket(AF_INET, SOCK_STREAM, 0 ); assert( sock >= 0 ); int ret = bind(sock, (struct sockaddr*)&address, sizeof (address) ); assert( ret != 1 ); ret = listen( sock, 5 ); assert( ret != 1 ); struct sockaddr_in client ; socklen_t clinet_addrlength = sizeof (client); int connfd = accept( sock, (struct sockaddr*)&client, &client_addrlength ); if ( connfd < 0 ) { printf ("errno is: %d\n" , errno); } else { char buffer[ BUF_SIZE ]; memset ( buffer, '\0' , BUF_SZIE ); ret = recv( connfd, buffer, BUF_SIZE-1 , 0 ); printf ("got %d bytes of normal data '%s'\n" , ret, buffer ); memset ( buffer, '\0' , BUF_SZIE ); ret = recv( connfd, buffer, BUF_SIZE-1 , MSG_OBB ); printf ("got %d bytes of obb data '%s'\n" , ret, buffer ); memset ( buffer, '\0' , BUF_SZIE ); ret = recv( connfd, buffer, BUF_SIZE-1 , 0 ); printf ("got %d bytes of normal data '%s'\n" , ret, buffer ); close( connfd ); } close( sock ); return 0 ; } got 5 bytes of normal data '123ab' got 1 bytes of obb data 'c' got 3 bytes of normal data '123'
b) UDP数据读写
socket编程中用于UDP数据报读写的系统调用:
1 2 3 4 5 6 #include <sys/types.h> #include <sys/socket.h> ssize_t recvfrom (int sockfd, void *buf, size_t len, int flags, struct sockaddr* src_addr , socklen_t *addrlen) ;ssize_t sendto (int sockfd, const void *buf, size_t len, int flags , const struct sockaddr *dest_addr, socklent_t addrlen) ;
UDP没有通信的概念,所以每次读取和发送数据都需要指定目标的socket地址。
该系统调用也可以用于面向连接的socket,只需要把最后两个参数设置为NULL,忽略地址。
c) 通用数据读写函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <sys/socket.h> ssize_t recvmsg ( int sockfd, struct msghdr *msg, int flags ) ;ssize_t sendmsg ( int sockfd, struct msghdr *msg, int flags ) ;struct msghdr { void *msg_name; socklen_t msg_namelen; struct iovec * msg_iov ; int msg_iovlen; void *msg_contorl; socklen_t msg_contorllen; int msg_flags; }; struct iovec { void *iov_base; size_t iov_len; };
iovec用于分散读和集中写。
msg_control,辅助数据,13章介绍如何使用它们来实现进程间传递文件描述符。
5.9 带外标记 前面演示了TCP带外数据的接收方法,但实际应用中,无法预期带外数据何时到来。所以有了如下系统调用:
1 2 #include <sys/socket.h> int sockatmark ( int sockfd ) ;
sockatmark判断sockfd是否处于带外标记,即下一个被读取的数据是否是带外数据。如果是返回1,此时就可以利用带MSG_OBB标志的recv调用来接收带外数据。
5.10 地址信息函数 用以知道本端的socket地址,以及远端的socket地址:
1 2 3 #include <sys/socket.h> int getsockname ( int sockfd, struct sockaddr* address, socklen_t *address_len ) ;int getpeername ( int sockfd, struct sockaddr* address, socklen_t *address_len ) ;
getsockname获取本端的,getpeername获取对端的。
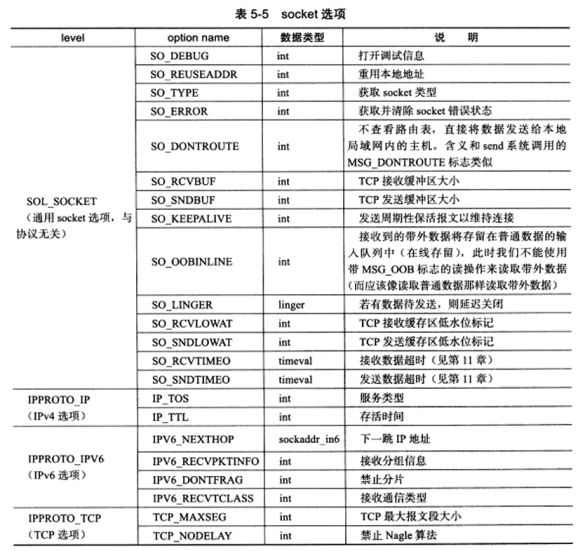
5.11 socket选项 下面两个系统调用用来读取和设置socket文件描述符属性:
1 2 3 4 5 #include <sys/socket.h> int getsockopt ( int sockfd, int level, int option_name, void *option_value, socklen_t *restrict option_len ) ;int setsockopt ( int sockfd, int level, int option_name, const void *option_value, socklen_t option_len ) ;
a) SO_REUSEADDR选项
通过设置该选项,强制使用处于被TIME_WAIT状态的连接占用的socket地址
1 2 3 4 5 6 7 8 9 10 11 12 int sock = socket( AF_INET ,SOCK_STREAM, 0 );assert( sock >= 0 ); int reuse = 1 ;setsockopt( sock, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeog( reuse ) ); struct sockaddr_in address ;bzero( &address, sizeof ( address ) ); address.sin_family = AF_INET; inet_pton( AF_INET, ip, &address.sin_addr ); address.sin_port = htons( port ); int ret = bind( sock, (struct sockaddr*)&address, sizeof ( address ) );
b) SO_RCVBUF和SO_SNDBUF选项
设置接收缓冲区和发送缓冲区的大小时,系统都会将其值加倍,并且不得小于某个最小值。TCP接收缓冲区的最小值是256,发送缓冲最小值是2048。目的是,确保一个TCP连接拥有足够的空间缓冲区来处理拥塞。通过之间修改内核参数可以强制其没有最小值限制。
执行如下:
可以看出50字节的设置没有成功,系统将其设置为了最小值256,2000成功了,且系统将其实际上加倍
c) SO_RCVLOWAT和SO_SNDLOWAT选项
SO_RCVLOWAT和SO_SNDLOWAT选项分别标识TCP接收缓冲区和发送缓冲区的低水位标记。一般用于I/O复用系统调用用来判断socket是否可读或可写。当TCP接收缓冲区中可读数据的总数大于其低水位标记时,通常读数据;当TCP发送缓冲区的空闲空间大于其低水位标记时,通知写数据。
一般默认值均为1字节。
d) SO_LINGER选项
SO_LINGER选项用来控制close系统调用在关闭TCP连接时的行为。默认情况下,close关闭socket,close立即返回,TCP模块负责把socket对应TCP发送缓冲区中残留的数据发送给对方。
设置该选项,需用传递一个linger类型的结构体:
1 2 3 4 5 #include <sys/socket.h> struct linger { int l_onoff; int l_linger; };
根据参数的不同有如下三种行为:
1) l_onoff等于0,此时该选项不起作用,与close默认类似
1) l_onoff不为0,l_linger等于0,此时close立即返回,丢弃残留的数据,同时发送一个复位报文段。因此,这种情况给服务器提供了异常终止一个连接的方法。
1) l_onoff不为0,l_linger大于0。此时close的行为取决于两个条件:一是被关闭的socket对应的发送缓冲区是否有残留数据,二是socket是阻塞的还是非阻塞的。对于阻塞的,close等待一段长为l_linger的时间,直到残留数据被发送完并且得到对方的确认。如果没有发送完并得到确认,返回-1并设置errno为EWOULDBLOCK。如果是非阻塞,close立即返回。
5.12 网络信息API 简单来说避免直接使用IP地址,通过之后的一些函数实现,主机名代替IP地址,服务名代替端口号
1 2 telnet 127.0.0.1 80 telnet localhost www
a) gethostbyname和gethostbyaddr
分别根据主机名获取主机的完整信息和根据IP地址获取主机的完整信息。
1 2 3 4 5 6 7 8 9 10 11 #include <netdb.h> struct hostent * gethostbyname ( const char * name ) ;struct hostent * gethostbyaddr ( const void * addr, size_t len, int type) ;struct hostent { char * h_name; char ** h_aliases; int h_addrtype; int h_length; char ** h_addr_list; };
b) getservbyname和getservbyport
根据名称获取某个服务的完整信息,和根据端口号获取。
1 2 3 #include <netdb.h> struct servent * getservbyname ( const char * name, const char * proto ) ;struct servent * getservbyport ( int port, const char * proto ) ;
proto参数指定服务类型,”tcp”标识获取流服务,”udp”标识获取udp服务,NULL标识所有服务类型。
1 2 3 4 5 6 7 #include <netdb.h> struct servent { char *s_name; char ** s_aliases; int s_port; char * s_proto; };
例子:通过主机名和服务名访问目标服务器上的daytime服务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <netinet/in.h> #include <netdb.h> #include <sys/socket.h> #include <stdio.h> #include <unistd.h> #include <assert.h> int main (int argc, char *argv[]) { assert( argc == 2 ); char *host = argv[1 ]; struct hostent *hostinfo = assert( hostinfo ); struct servent *servinfo ="daytime" , "tcp" ); assert( servinfo ); printf ( "daytime port is %d\n" , ntohs( servinfo->s_port ) ); struct sockaddr_in address ; address.sin_family = AF_INET; address.sin_port = servinfo->s_port; address.sin_addr = *( struct in_addr* )*hostinfo->h_addr_list; int sockfd = socket( AF_INET, SOCK_STREAM, 0 ); int result = connect( sockfd, (struct sockaddr*)&address, sizeof ( address ) ); assert( result != -1 ); char buffer[128 ]; result = read( sockfd, buffer, sizeof ( buffer ) ); assert( result > 0 ); buffer[result] = '\0' ; printf ( "the day time is: %s" , buffer ); close( sockfd ); return }
c) getaddrinfo
getaddrinfo既能通过主机名获取IP地址,也能通过服务名获取端口号
1 2 3 #include <netdb.h> int getaddrinfo (const char *hostname, const char *service, const struct addrinfo *hints, struct addrinfo ** result) ;
hitns参数用以给getaddrinfo一个目标期望,resulst参数指向一个链表,用于存储反馈结果。
1 2 3 4 5 6 7 8 9 10 struct addrinfo { int ai_flags; int ai_family; int ai_socktype; int ai_protocol; socklen_t ai_addrlen; char *ai_canonname; struct sockaddr *ai_addr ; struct addrinfo *ai_next ; };
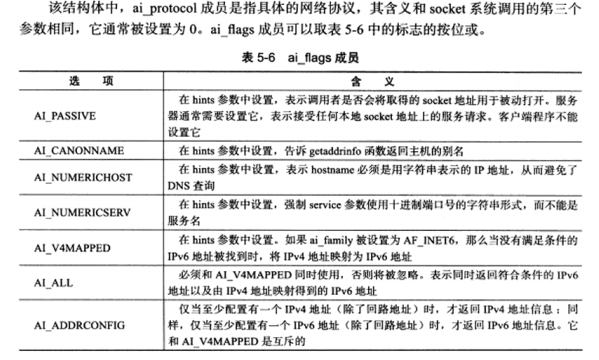
当我们使用hints参数时,可以设置其ai_flags,ai_family,ai_socktype和ai_protocol四个字段,用法如下:
1 2 3 4 5 6 struct addrinfo hints ;struct addrinfo *res ;bzero( &hitns, sizeof (hints) ); hints.ai_socktype = SOCK_STREAM; getaadrinfo( "ernest-laptop" , "daytime" , &hints, &res);
表示只获取主机ernest-laptop上daytime的流服务,也就是TCP服务。
在getaddrinfo调用结束后,使用如下函数释放内存:
1 2 #include <netdb.h> void freeaadrinfo ( struct addrinfo *res ) ;
d) getnameinfo
getnameinfo函数能通过socket地址同时获得以字符串表示的主机名和服务名。
1 2 3 #include <netdb.h> int getnameinfo ( const struct sockaddr *sockaddr, socklen_t addrlen, char *host, socklen_t hostlen, char *serv, socklen_t servlen, int flags) ;
flags参数控制getnameinfo的行为,如下:
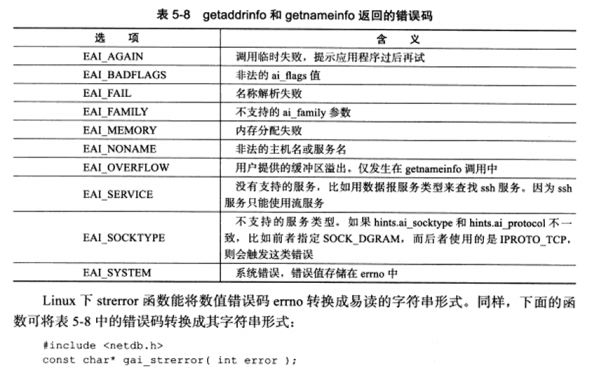
失败时返回的错误码表如下:
第6章 高级I/O函数 诸如pipe,dup/dup2等这类函数的介绍
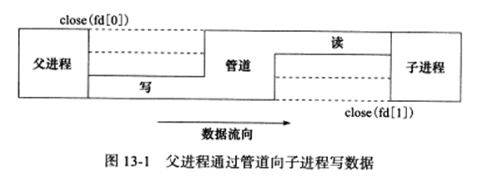
6.1 pipe函数 pipe函数可用于创建一个管道,以实现进程间通信。本章只讨论基本使用方式:
1 2 #include <unistd.h> int pipe (int fd[2 ]) ;
fd[0]和fd[1]分别构成管道的两端,fd[1]为写端,fd[0]为读端。并且是单向的,如果要实现双向的数据传输,需要两根管道。如果管道的写端fd[1]的引用计数减少至0,针对该管道的读端fd[0]的read操作将返回0,即读到文件结束标记(EOF)。反之如果读端fd[0]的引用计数减少至0,针对该管道的写端fd[1]的write操作将失败,并引发SIGPIPE信号。
管道本身拥有一个容量限制,大小默认是65535字节。可以使用fcntl来修改。
此外,socket的基础api种有一个socketpari函数。用以方便地创建双向管道:
1 2 3 #include <sys/types.h> #include <sys/socket.h> int socketpair (int domain, int type, int protocol, int fd[2 ]) ;
前三个参数和socket的参数完全相同,但domain只能使用UNIX本地域协议族AF_UNIX,因为仅能在本地使用。
6.2 dup函数和dup2函数 重定向文件描述符,比如将标准输入重定向到一个文件。可以通过如下用于复制文件描述符的dup/dup2函数实现:
1 2 3 #include <unistd.h> int dup (int file_descriptor) ;int dup2 (int file_descriptor_one, int file_descriptor_two) ;
利用函数实现一个基本GGI服务器例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <string.h> int main ( int argc, char *argv[] ) { if ( argc<=2 ) { printf ("usage: ...." ); return 1 ; } const char *ip = argv[1 ]; int prot = atoi( argv[2 ] ); struct sockaddr_in address ; bzero( &address, sizeof ( address ) ); address.sin_family = AF_INET; inet_pton( AF_INET, ip, &address.sin_addr ); address.sin_port = htons( port ); int sock = socket( AF_INET, SOCK_STREAM, 0 ); assert( sock>=0 ); int ret = bind( sock, (struct sockaddr*)&address, sizeof ( address ) ); assert( ret!=-1 ); ret = listen( sock, 5 ); assert( ret!=-1 ); struct sockaddr_in client ; socklen_t cli_len = sizeof ( client ); int connfd = accept( sock, (struct sockaddr*)&client, &cli_len ); if ( connfd<0 ) { printf ( "errno is: %d\n" , errno ); } else { close( STDOUT_FILENO ); dup( connfd ); printf ( "abcd\n" ); close( connfd ); } close( sock ); return 0 ; }
首先关闭标准输出,此时dup的特性,返回最小可用的文件描述符,即此时标志输出被重定向到connfd,此时的printf将直接发送到connfd连接的socket上。
6.3 readv函数和writev函数 集中写和分散读函数:
1 2 3 #include <sys/uio.h> ssize_t readv (int fd, const struct iovec *vector , int count) ;ssize_t writev (int fd, const struct iovec *vector , int count) ;
考略之前的Web服务器,当Web服务器解析完一个HTTP请求后,如果目标文档存在且客户具有读权限,那么就要发送一个HTTP应答。这个HTTP应答包含一个状态行,多个头部字段,一个空行和文档的内容,前三部分内容可能存放在一块内存,文档的内容则在另一块单独的内存,此时可以用集中写,将他们一起写出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <string.h> #include <sys/stat.h> #include <fcntl.h> #icnlude <sys/types.h> #define BUFFER_SZIE 1024 static const char *status_line[2 ] = { "200 ok" , "500 Internal server error" };int main ( int argc, char *argv[] ) { if ( argc<=3 ) { printf ( "usage: ... " ); return 1 ; } const char *ip = argv[1 ]; int port = atoi( argv[2 ] ); const char *file_name = argv[3 ]; struct sockaddr_in address ; bzero( &address, sizeof ( address ) ); address.sin_family = AF_INET; inet_pton( AF_INET, ip, &address.sin_addr ); address.sin_port = htons( port ); int sock = socket( AF_INET, SOCK_STREAM, 0 ); assert( sock>=0 ); int ret = bind( sock, (struct sockaddr*)&address, sizeof ( address ) ); assert( ret!=-1 ); ret = listen( sock, 5 ); assert( ret!=-1 ); struct sockaddr_in client ; socklen_t cli_len = sizeof ( client ); int connfd = accept( sock, (struct sockaddr*)&client, &cli_len ); if ( connfd<0 ) { printf ( "errno is: %d\n" , errno ); } else { char header_buf[BUFFER_SIZE]; memset ( header_buf, '\0' , BUFFER_SIZE ); char *file_buf; struct stat file_stat ; bool valid = true ; int len = 0 ; if ( stat( file_name, &file_stat) < 0 ) { valid = false ; } else { if ( S_ISDIR( file_stat.st_mode ) ) { valid = false ; } else if ( file_stat.st_mode & S_IROTH ) { int fd = open( file_name, O_RDONLY ); file_buf = new char [file_stat.st_size + 1 ]; memset ( file_buf, '\0' , file_stat.st_size + 1 ); if ( read( fd, file_buf, file_stat.st_size ) < 0 ) { valid = false ; } } else { valid = false ; } } if ( valid ) { ret = snprintf ( header_buf, BUFFER_SIZE-1 , "%s %s\r\n" , "HTTP/1.1" , status_line[0 ] ); len+=ret; ret = snprintf ( header_buf+len, BUFFER_SIZE-1 -len, "Content-Length: %d\r\n" , file_stat.st_size ); len+=ret; ret = snprintf ( header_buf+len, BUFFER_SIZE-1 -len, "%s" , "\r\n" ); struct iovec iv [2]; iv[0 ].iov_base = header_buf; iv[0 ].iov_len = strlen ( header_buf ); iv[1 ].iov_base = file_buf; iv[1 ].iov_len = file_stat.st_size; ret = writev( connfd, iv, 2 ); } else { ret = snprintf ( header_buf, BUFFER_SIZE-1 , "%s %s\r\n" , "HTTP/1.1" , status_line[1 ] ); len+=ret; ret = snprintf ( header_buf+len, BUFFER_SIZE-1 -len, "%s" , "\r\n" ); send( connfd, header_buf, strlen ( header_buf ), 0 ); } close( connfd ); delete [] file_buf; } close( sock ); return 0 ; }
6.4 sendfile函数 sendfile在两个文件描述符之间直接传递数据,完全在内核种操作,避免了内核缓存区和用户缓冲区之间的数据拷贝,效率很高,被称为零拷贝。
1 2 #include <sys/sendfile.h> ssize_t sendfile (int out_fd, int in_fd, off_t *offset, size_t count) ;
in_fd是待读出内容的文件描述符,out_fd是待写入内容的文件描述符,offset为读入文件流的偏移位置,count为拷贝字节数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <errno.h> #include <string.h> #include <sys/stat.h> #include <fcntl.h> #icnlude <sys/types.h> #include <sys/sendfile.h> int main ( int argc, char *argv[] ) { if ( argc<=3 ) { printf ("usage: ... " ); return 1 ; } const char *ip = argv[1 ]; int prot = atoi( argv[2 ] ); const char *file_name = argv[3 ]; int filefd = open( file_name, O_RDONLY ); assert( filefd>0 ); struct stat stat_buf ; fstat( filfd, &stat_buf ); struct sockaddr_in address ; bzero( &address, sizeof ( address ) ); address.sin_family = AF_INET; inet_pton( AF_INET, ip, &address.sin_addr ); address.sin_port = htons( port ); int sock = socket( AF_INET, SOCK_STREAM, 0 ); assert( sock>=0 ); int ret = bind( sock, (struct sockaddr*)&address, sizeof ( address ) ); assert( ret!=-1 ); ret = listen( sock, 5 ); assert( ret!=-1 ); struct sockaddr_in client ; socklen_t cli_len = sizeof ( client ); int connfd = accept( sock, (struct sockaddr*)&client, &cli_len ); if ( connfd<0 ) { printf ( "errno is: %d\n" , errno ); } else { sendfile( connfd, filefd, NULL , stat_buf.st_size ); close( connfd ); } close( sock ); return 0 ; }
6.5 mmap函数和munmap函数 mmap函数用于申请一段内存空间。可用将这段内存作为进程间通信的共享内存,也可以直接将文件映射到其中。mumap函数则释放mmap创建的这段内存:
1 2 3 #include <sys/mman.h> void *mmap (void *start, size_t length, int prot, int flags, int fd, off_t offset) ;int munmap (void *start, size_t length) ;
start参数允许用户使用某个特定的地址作为其实地址,设置为NULL,则系统自动分配一个地址。prot参数用来设置内存段的访问权限,可取以下几个值的按位或:
PROT_READ,内存段可读。
PROT_WRITE,内存段可写。
PROT_EXEC,内存段可执行。
PROT_NONE,内存段不能被访问。
flags参数控制内存段内容被修改后程序的行为。如下表,其中MAP_SHARED和MAP_PRIVATE是互斥的,不能同时指定:
6.6 splice函数 splice函数用于在两个文件描述符之间移动数据,也是零拷贝操作。
1 2 3 #include <fcntl.h> ssize_t splice (int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags) ;
fd_in是待输入数据的文件描述符。
flags参数的常用值:
使用splice函数时,fd_in和fd_out必须至少有一个时管道文件描述符。splice函数常见的errno如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 #include <sys/socket.h> #include <netinte/in.h> #include <arpa/inet.h> #inlcude <assert.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <fcntl.h> int main ( int argc, char *argv[] ) { if ( argc<=2 ) { printf ("usage: ... " ); return 1 ; } const char *ip = argv[1 ]; int port = atoi( argv[2 ] ); struct sockaddr_in address ; bzero( &address, sizeof ( address ) ); address.sin_family = AF_INET; inet_pton( AF_INET, ip, &address.sin_addr ); address.sin_port = htons( port ); int sock = socket( AF_INET, SOCK_STREAM, 0 ); assert( sock>=0 ); int ret = bind( sock, (struct sockaddr*)&address, sizeof ( address ) ); assert( ret!=-1 ); ret = listen( sock, 5 ); assert( ret!=-1 ); struct sockaddr_in client ; socklen_t cli_len = sizeof ( client ); int connfd = accept( sock, (struct sockaddr*)&client, &cli_len ); if ( connfd<0 ) { printf ( "errno is: %d\n" , errno ); } else { int pipefd[2 ]; assert( ret != -1 ); ret = pipe( pipefd ); ret = splice( connfd, NULL , pipefd[1 ], NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE ); assert( ret != -1 ); ret = splice( pipifd[0 ], NULL , connfd, NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE ); assert( ret != -1 ); close( connfd ); } close( sock ); return 0 ; }
6.7 tee函数 tee函数在两个管道文件描述符之间复制数据,也是零拷贝操作。
1 2 #include <fcntl.h> ssize_t tee (int fd_in, int fd_out , size_t len, unsigned int flags) ;
参数和splice一致,但fd_in和fd_out必须都是管道。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <assert.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> int main ( int argc, char *argv[] ) { if ( argc !=2 ) { printf ("usage: ... " ); return 1 ; } int filefd = open( argv[1 ], O_CREAT | O_WRONLY | O_TRUNC, 0666 ); assert( filefd>0 ); int pipefd_stdout[2 ]; int ret = pipe( pipefd_stdout ); assert( ret!=-1 ); ret = splice( STDIN_FILENO, NULL , pipefd_stdout[1 ], NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE ); assert( ret!=-1 ); ret = tee( pipefd_stdout[0 ], pipefd_file[1 ], 32768 , SPLICE_F_NONBLOCK ); assert( ret!=-1 ); ret = splice( pipefd_file[0 ], NULL , filefd, NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE ); assert( ret !=-1 ); ret = splice( pipefd_stdout[0 ], NULL , STDOUT_FILENO, NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE ); assert( ret!=-1 ); close( filefd ); close( pipefd_stdout[0 ] ); close( pipefd_stdout[1 ] ); close( pipefd_file[0 ] ); close( pipefd_file[1 ] ); return 0 ; }
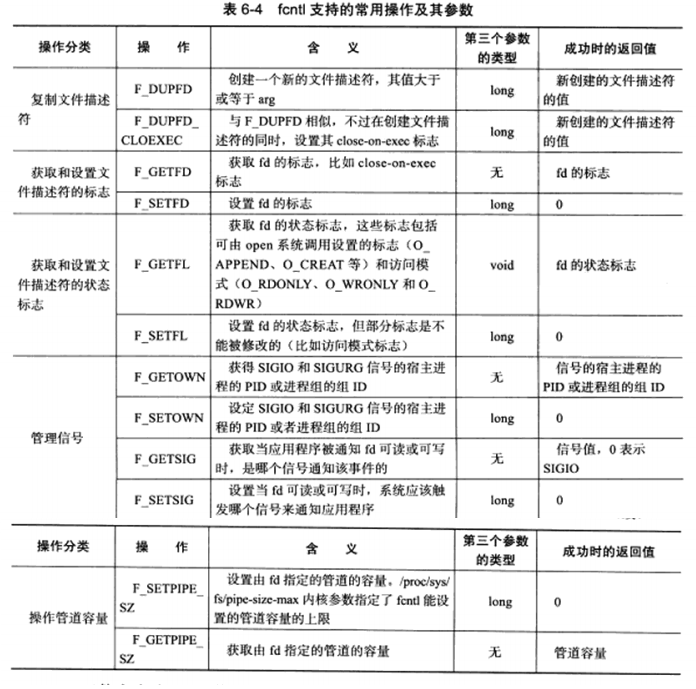
6.8 fcntl函数 1 2 #include <fcntl.h> int fcntl (int fd, int cmd, ...) ;
支持的常用操作如下表:
1 2 3 4 5 6 7 8 int setnonblocking (int fd) { int old_option = fcntl( fd, F_GETFL ); int new_option = old_option | O_NONBLOCK; fcntl( fd, F_SETFL, new_option ); return old_option; }
第7章 Linux服务器程序规范 服务器程序的常见模板:
以守护进程运行,拥有一套日志系统,以某个专门的非root身份运行,通常可配置的也就是拥有配置文件,通常会在启动的时候生成一个PID文件并存入/var/run目录,通常需要考虑系统资源和限制。
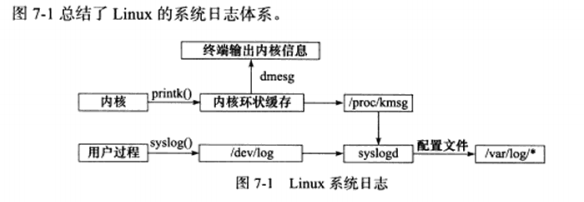
7.1 日志 a) Linux系统日志
Linux提供一个守护进程来处理系统日志——syslogd,现在使用的为它的升级版——rsyslogd。
分为内核输出的日志和用户输出的日志。
内核:由printk等函数打印至内核的环状缓存(ring buffer)中。环状缓存的内容直接映射到/proc/ kmsg文件中。
用户:通过调用syslog函数生成系统日志,该函数将日志输出到一个UNIX本地域socket类型的文件/dev/log中,rsyslogd则监听该文件以获取用户进程的输出。
rsylogd守护进程在接收到用户进程或内核输入的日志后,会把它们输出至某些特定的日志文件。默认情况下,调式信息会保存至/var/log/debug文件,普通信息/var/log/message文件,内核消息/var/log/kern/loh文件。日志信息具体如何分发,可在rsyslogd的配置文件中设置。
b) syslog函数
应用程序使用syslog函数与rsylogd守护进程通信:
1 2 #include <syslog.h> void syslog (int priority, const char *message, ...) ;
priority参数是所谓的设施值与日志级别的按位或。设施值的默认值是LOG_USER,下面的讨论仅限于该值。日志级别如下:
1 2 3 4 5 6 7 8 9 #include <syslog.h> #define LOG_EMERG 0 #define LOG_ALERT 1 #define LOG_CRIT 2 #define LOG_ERR 3 #define LOG_WARNING 4 #define LOG_NOTICE 5 #define LOG_INFO 6 #define LOG_DEBUG 7
下面这个函数可改变syslog的默认输出方式,进一步结构化日志内容:
1 2 #include <syslog.h> void openlog (const char *ident, int logopt, int facility) ;
ident参数指定的字符串将被添加到日志消息的日期和时间之后,它通常被设置为程序的名字。logopt参数对后续syslog调用的行为进行配置,它可取下列值的按位或:
1 2 3 4 #define LOG_PID 0X01 #define LOG_CONS 0X02 #define LOG_ODELAY 0X04 #define LOG_NDELAY 0X08
facility参数可用来修改syslog函数中的默认值。
下面这个函数用于设置syslog的日志掩码:
1 2 #include <syslog.h> int setlogmask (int maskpri) ;
如下函数关闭日志功能:
1 2 #include <syslog.h> void closelog () ;
7.2 用户信息 a) UID, EUID, GID 和 EGID
下面这一组函数可用获取和设置当前进程的真实用户ID(UID),有效用户ID(EUID),真实组(GID)和有效组(EGID):
1 2 3 4 5 6 7 8 9 10 #include <sys/types.h> #include <unistd.h> uid_t getuid () ; uid_t seteuid () ;gid_t getgid () ;gid_t getegid () ;int setuid (uid_t uid) ;int seteuid (uid_t uid) ;int setgid (gid_t gid) ;int setegid (gid_t gid) ;
测试进程的UID和EUID的区别:
1 2 3 4 5 6 7 8 9 #include <unistd.h> #include <stdio.h> int main () { uid_t uid = getuid(); uid_t euid = geteuid(); printf ( "userid is %d, effectie userid is %d\n" , uid, euid ); return 0 ; }
编译该文件,将生成的可执行文件(test_uid)的所有者设置为roort,并设置该文件的set-user-id标志,然后运行该程序查看UID和EUID:
1 2 3 4 $ sudo chown root:root test_uid $ sudo chmod +s test_uid $ ./test_uid userid is 1000 , effective userid is 0
可看出进程的UID是启动用户的ID,而EUID则是root账户的ID
b) 切换用户
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static bool switch_to_user (uid_t user_id, gid_t gp_id) { if ( ( user_id == 0 ) && (gp_id == 0 ) ) { return false ; } gid_t gid = getgid(); uid_t uid = getuid(); if ( ( (gid != 0 ) || (uid != 0 ) ) && ( (gid != gp_id ) || ( uid != user_id ) ) ) { return false ; } if ( uid != 0 ) { return true ; } if ( ( setgid( gp_id ) < 0 ) || ( setuid( user_id ) < 0 ) ) { return false ; } return true ; }
7.3 进程间关系 a) 进程组
每个进程都属于一个进程组,除了它们的PID信息外,还有进程组ID(PGID):
1 2 #included <unistd.h> pid_t getpgid (pid_t pid) ;
每个进程都有一个首领进程,其PGID和PID相同。进程组将一直存在,直到其中所有进程都退出或加入其他的进程组。
下面的函数用于设置PGID:
1 2 #include <unistd.h> int setpgid (pid_t pid, pid_t pgid) ;
将PID为pid的进程的PGID设置为pgid,如果pid和pgid相同,则由pid指定的进程将被设置为进程组首领。如果pid为0,则表示设置当前进程的PGID为pgid,如果pgid为0,则使用pid作为目标PGID。
b) 会话
一些有关联的进程组将形成一个会话,下面的函数用于创建一个会话:
1 2 #include <unistd.h> pid_t setsid (void ) ;
该函数不能由进程组的首领进程调用,否则将产生一个错误。对于非组首领的进程,调用函数不仅创建新会话,而且有如下额外效果:
调用进程成为会话的首领,此时该进程是新会话的唯一成员。
新建一个进程组,其GPID就是调用进程的PID,调用进程成为改组的首领。
调用进程将甩开终端。
如下函数读取会话ID(SID):
1 2 #include <unistd.h> pid_t getsid (pid_t pid) ;
c) 用ps命令查看进程关系
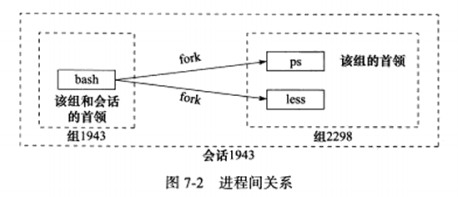
1 2 3 4 5 $ ps -o pid,ppid,pgid,sid,comm | less PID PPID PGID SID COMMAND 1943 1942 1943 1943 bash2298 1943 2298 1943 ps2299 1942 2298 1943 less
三者关系如下图:
7.4 系统资源限制 Linux系统资源限制可用通过如下一对函数来读取和设置:
1 2 3 4 5 6 7 8 #include <sys/resuorce.h> int getrlimit (int resource, struct rlimit *rlim) ;int setrlimit (int resource, const struct rlimit *rlim) ;struct rlimit { rlim_t rlim_cur; rlim_r rlim_max; }
rlim_cur指定资源的软限制,rlim_max指定资源的硬限制。软限制是一个建议性的,最好不要超越的限制,如果超越的话,系统可能向进程发送信号以终止其运行。硬限制一般是软限制的上限,普通程序可减小硬限制,而只有root身份运行的程序才能增加硬限制。下图列举了部分比较重要的资源限制类型:
7.5 改变工作目录和根目录 有的服务器程序需要改变工作目录。如前面讨论的Web服务器。
获取当前工作目录和改变进程工作目录的函数分别是:
1 2 3 #include <unistd.h> char *getcwd (char *buf, size_t size) ;int chdir (const char *path) ;
改变进程根目录的函数是chroot,其定义如下:
1 2 #include <unistd.h> int chroot (const char *path) ;
chroot并不改变进程的当前工作目录,所以调用chroot之后,我们仍然需要使用chdir(“/“)来将工作目录切换至新的根目录。此外,只有特权进程才能改变根目录。
7.6 服务器程序后台化 讨论在代码中如何让一个进程以守护进程的方式运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 bool daemonize () { pid_t pid = fork(); if ( pid < 0 ) { return false ; } else if ( pid > 0 ) { exit (0 ); } umask( 0 ); pid_t sid = setsid(); if ( sid < 0 ) { return false ; } if ( ( chdir( "/" ) ) < 0 ) { return false ; } close( STDIN_FILENO ); close( STDOUT_FILENO ); close( STDERR_FILENO ); . . . . . . open( "dev/null" , O_RDONLY ); open( "dev/null" , O_RDWR ); open( "dev/null" , O_RDWR ); return true ; }
Linux提供了完成同样功能的库函数:
1 2 #include <unistd.h> int daemon (int nochdi, int noclose) ;
nochdir参数用于指定是否改变工作目录,为0则设置为”/“,否则继续使用当前。
nclose参数为0时,标准输入,输出,错误都被重定向到/dev/null文件,否则依然使用原来的设备。
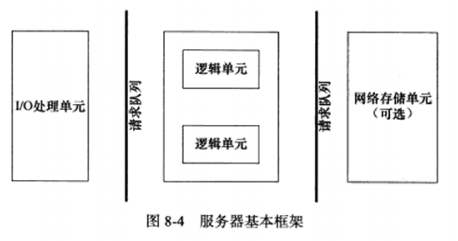
第8章 高性能服务器程序框架 按照服务器程序的一般原理,将服务器解构成三个模块:
I/O处理单元,逻辑单元,存储单元。
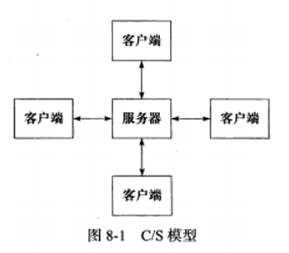
8.1 服务器模型 a) CS模型
最常见的客户端,服务端模型。
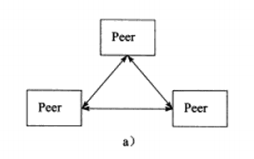
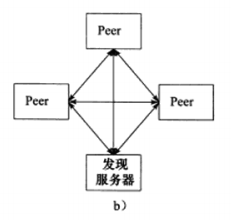
b) P2P模型
摒弃了以服务器为中心的格局,网络上所有主机重新回归对等的地位。
P2P模型使得每台机器在消耗服务的同时也能给别人提供服务,这样资源能够充分,自由地共享。P2P模型存在一个显著的问题,即主机之间很难互相发现。所以实际使用的P2P模型通常带有一个专门的发现服务器,提供查找服务,使每个客户能尽快的找到自己需要的资源。
8.2 服务器编程框架 基本框架如下:
模块
单个服务器程序
服务器机群
I/O处理单元
处理客户连接,读写网络数据
作为接入服务器,实现负载均衡
逻辑单元
业务进程或线程
逻辑服务器
网络存储单元
本地数据库,文件或缓存
数据库服务器
请求队列
各单元之间的通信方式
各服务器之间的永久TCP连接
请求队列是各个单元之间通信方式的抽象,I/O处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。请求队列通常被实现为池的一部分。
8.3 I/O模型 I/O模型对比:
I/O模型
读写操作和阻塞阶段
阻塞I/O
程序阻塞于读写函数
I/O复用
程序阻塞于I/O复用系统调用(如select),但可同时监听多个I/O事件。对I/O本身的读写操作是非阻塞的
SIGIO信号
信号触发读写就绪事件,用户程序执行读写操作。程序没有阻塞阶段
异步I/O
内核执行读写操作并触发读写完成事件。程序没有阻塞阶段
针对非阻塞I/O执行的系统调用总是立即返回,而不管事件是否已经发生。如果没有立即发生,返回-1和出错的情况一样。此时需要根据errno来区分这两种情况。
8.4 两种高效的事件处理模式 同步I/O常用于实现Reactor模式,异步I/O则用于实现Proactor模式。
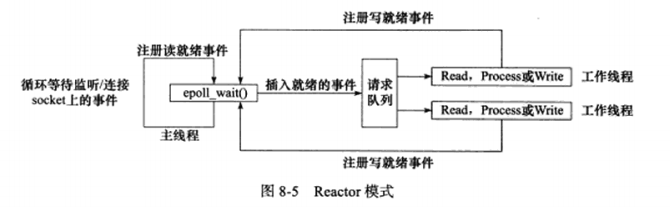
a) Reactor模式
该模式,要求主线程(I/O处理单元)只负责监听文件描述符是否有事件发生,有的话立即将该事件通知工作线程(逻辑单元)。除此之外,主线程不做任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程完成。
使用同步I/O模型(epoll_wait)实现的的Reactor模型流程如下:
主线程往epoll内核事件表中注册socket上的读就绪事件。
主线程调用epoll_wait等待socket上有数据可读。
当socket可读时,epoll_wait通知主线程。主线程则将socket可读事件放入请求队列。
睡眠在请求队列上的工作线程被唤醒,它从socket读取数据,并处理客户请求,然后往epoll内核事件表注册该socket的写就绪事件。
主线程调用epoll_wait等待socket可写。
当socket可写时,epoll_wait通知主线程。主线程则将socket可写事件放入请求队列。
睡眠在请求队列上的工作线程被唤醒,它往socket上写入服务器处理客户请求的结果。
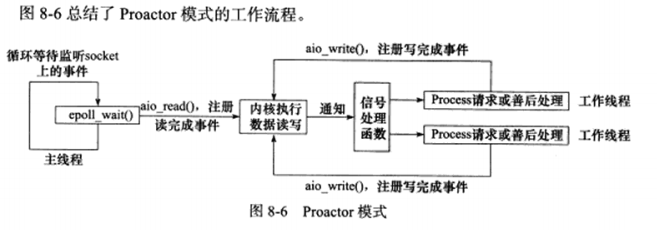
b) Proactor模式
Proactor模式将所有的I/O操作交给主线程和内核来处理,工作线程仅负责业务逻辑。因此,该模式更符合前面所描述的服务器编程框架。
使用异步I/O模型(以aio_read和aio_write为例)实现的Proactor模式的流程如下:
主线程调用aio_read函数向内核注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序(这里以信号为例)。
主线程继续处理其他逻辑。
当socket上的数据被读入用户缓冲区后,内核向应用程序发送一个信号,以通知应用程序数据已经可用。
应用程序预先定义好的信号处理函数选择一个工作线程来处理该客户请求。工作线程处理完客户请求后,调用aio_write函数向内核注册该socket上的写完成事件,并告诉内核用户写缓冲区的位置,以及写操作完成时如何通知应用程序。
主线程继续处理其他逻辑。
当用户缓冲区的数据被写入socket之后,内核向应用程序发送一个信号,通知应用程序数据已发送完毕。
应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如是否关闭socket
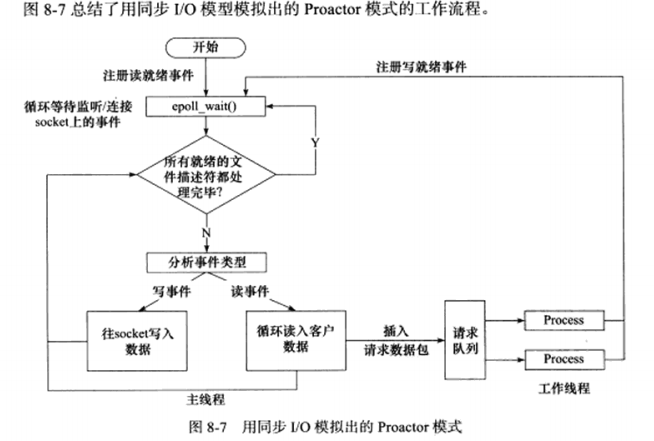
c) 模拟Proactor模式
使用同步I/O方式模拟出Proactor模式的一种方法。简单来说将数据读写操作这一工作,从逻辑单元移交给I/O处理单元,读写完成后,主线程向工作线程通知这一”完成事件”。
使用同步I/O模型(epoll_wait)模拟出的Proactor模式的流程如下:
主线程往epoll内核事件表注册socket上的读就绪事件。
主线程调用epoll_wait等待socket上有数据可读。
当socket上有数据可读时,epoll_wait通知主线程。主线程从socket循环读取数据,读完后,将读到的数据封装成一个请求对象并插入请求队列。
睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理该客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件。
主线程调用epoll_wait等待socket可写。
当socket可写时,epoll_wati通知主线程。主线程往socket上写入服务器处理客户请求的结果。
8.5 两种高效的并发模式 并发编程的目的简单来说为了提高程序的效率。对于计算密集型来说,并发没有优势,反而因为任务的切换使得效率降低。但对于I/O密集型,比如经常读写文件,访问数据库。由于I/O操作的速度远没有CPU的计算速度快,让程序阻塞于I/O操作将浪费大量的CPU事件。因此,并发可使CPU的利用率显著提升。
并发模式是指I/O处理单元和多个逻辑单元之间协调完成任务的方法。服务器主要有两种并发编程模式:半同步/半异步(half-sync/half-async)模式和领导者/追随者(Leader/Followers)模式。
a) 半同步/半异步模式
此处的同步/异步和I/O模型中的同步/异步是完全不同的概念。
I/O模型:同步和异步区分的是内核向应用程序通知的是何种I/O事件(就绪事件 or 完成事件),以及由谁来完成I/O读写(应用程序 or 内核)。
并发模式:同步是指程序完全按照代码序列的顺序执行,异步是指程序的执行需要由系统事件来驱动。常见的系统事件包括中断,信号等。
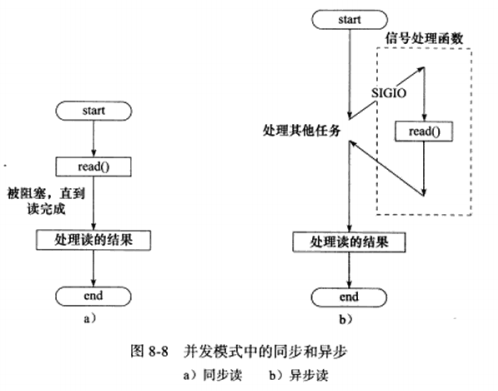
下图a描述了同步的读操作,b描述了异步的读操作:
按同步方式运行的线程称为同步线程,异步方式则称为异步线程。异步效率高,复杂;同步效率低,简单。
同步线程用于处理客户逻辑,即逻辑单元;异步线程处理I/O事件,即I/O处理单元。
异步线程监听到客户请求后,将其封装成请求对象插入请求队列。请求队列通知某个工作在同步模式的工作线程来读取并处理该请求对象。
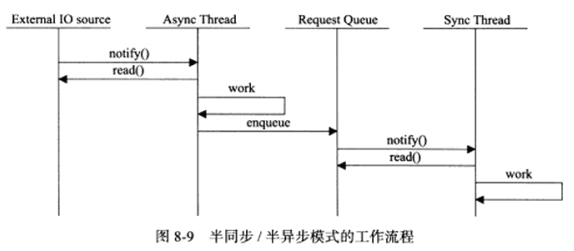
半同步/半异步模式的变体,半同步/半反应堆模式:
异步线程只有主线程,主线程插入请求队列的任务是就绪的连接socket。这说明改图采用的事件处理模式是Reactor模式:它要求工作线程自己从socket上读取客户请求和往socket写入服务器应答。这也是该模式半反应堆的含义。该模式存在如下缺点:
主线程和工作线程共享请求队列。主线程往请求队列中添加任务,或者工作线程从请求队列中取出任务,都需要对请求队列加锁保护,从而耗费CPU时间。
每个工作线程在同一时间只能处理一个客户请求。如果客户数量较多,工作线程较少,请求队列中任务对象越堆越多,客户端响应速度将越来越慢。
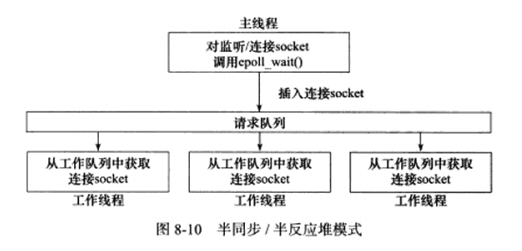
下图描述了一种相对高效的半同步/半异步模式:
主线程只管监听socket,连接socket由工作线程来管理,此后该新socket上的任何I/O操作都由被选中的工作线程来处理,直到客户关闭连接。
可见每个线程都维持自己的事件循环,它们各自独立地监听不同的事件。
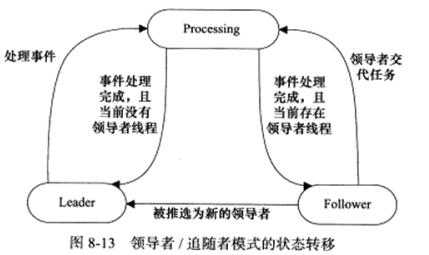
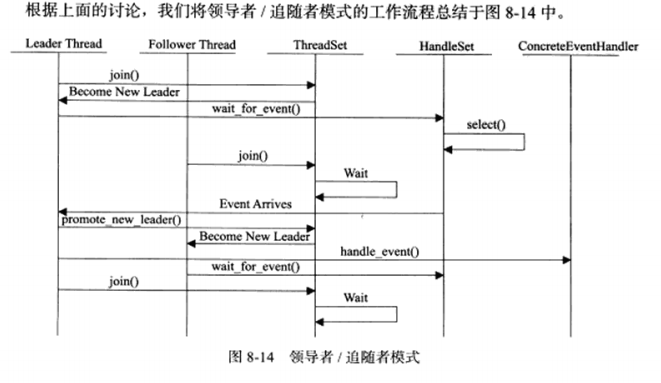
b) 领导者/追随者模式
该模式是多个工作线程轮流获得事件源集合,轮流监听,分发并处理事件的一种模式。任何时间,程序仅有一个领导者,它负责监听I/O事件。当前领导者如果检测到I/O事件,首先从线程池中推选出新的领导者线程,然后处理I/O事件。此时,新的领导者等待新的I/O事件,原先的领导者则处理I/O事件。
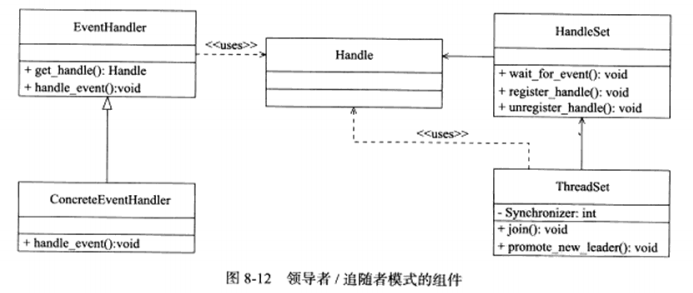
领导者/追随者模式包含如下几个组件:句柄集(HandleSet),线程集(ThreadSet),事件处理器(EventHandler)和具体的事件处理器(ConcreteEventHandler)。
1.句柄集 :
句柄用于表示I/O资源,句柄集管理众多句柄,它使用waif_for_event方法来监听句柄上的I/O事件,并将其中的就绪事件通知给领导者线程。领导者则调用绑定在Handle上的事件处理器来处理事件。领导者将Handle和事件处理器绑定是通过调用句柄集中的register_handle方法实现的。
2.线程集:
所有工作线程的管理者,负责各线程之间的同步,以及新领导者线程的推选,任一线程必处于如下三种状态之一:
Leader:线程当前处于领导者线程,负责等待句柄集上的I/O事件。
Processing:线程正在处理事件。领导者检测到I/O之间之后,转移到该状态来处理事件,并调用promote_new_leader方法推选新的领导者;也可以指定其他追随者来处理时间,此时领导者地位不变。当处于Processing状态的线程处理完后,如果没有领导者,它将称为领导者,反之称为追随者。
Follower:线程当前处于追随者身份。通过调用join方法等待称为新的领导者,也可能被领导指定处理新任务。
3.事件处理器和具体的事件处理器
事件处理器通常包含一个或多个回调函数handle_event。这些回调函数用于处理事件对应的业务逻辑。事件处理器在使用之前需要被绑定到某个句柄之上。具体的事件处理器是事件处理器的派生类。它们必须重新实现基类的handle_event方法,以处理特定的任务。
由于领导者线程自己监听I/O并处理客户请求,因此不需要在线程之间传递任何额外的数据,也无需像半同步/半反应堆那样在线程之间同步堆请求队列的访问。
8.6 有限状态机 此节介绍逻辑单元内部的一种高效编程方法:有限状态机
有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑,如下。
1 2 3 4 5 6 7 8 9 10 11 12 STATE_MACHINE ( Package_pack ) { PackageType _type = _pack.GetType(); switch ( _type ) { case type_A: process_package_A( _pack ); break ; case type_B: process_package_B( _pack ); break ; } }
这就是一个简单的有限状态机,但每个状态都是相互独立的,之间没有相互转移。状态之间的转移是需要状态机内部驱动的,如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 STATE_MACHINE () { State cur_State = type_A; while ( cur_State != type_C) { package _pack = getNewPackage(); switch ( cur_State ) { case type_A: process_package_state_A( _pack ); cur_State = type_B; break ; case type_B: process_package_state_B( _pack ); cur_State = type_C; break ; } } }
该状态机包含三种状态:type_A,type_B,type_C,A为开始状态,C为结束状态,通过curState判断以及给他传递状态值实现状态转移。
下面考虑有限状态机应用的一个实例:*HTTP请求的读取和分析 *。
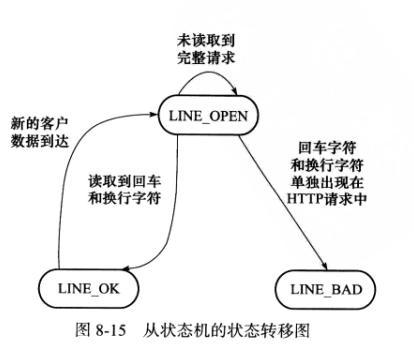
很多网络协议,在头部提供长度字段,根据该字段的值可以直到是否接收到一个完整的协议头部。但HTTP协议并未提供这样的头部长度字段,并且头部长度变化很大。根据协议规定,我们判断HTTP头部结束的依据是遇到一个空行,该空行仅包含一对回车换行符()。
如果一次读操作没有读入HTTP请求的整个头部,即没有遇到空行,那么我们需要等待客户继续写数据并再次读入。因此我们每完成一次读操作,需要分析新读入的数据中是否有空行。不过在寻找空行的过程中,我们可以同时完成对整个HTTP请求头部的分析(空行前面还有请求行和头部域),以提高HTTP请求的效率。
如下代码使用主,从两个有限状态机实现了最简单的HTTP请求的读取和分析。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #define BUFFER_SIZE 4096 enum CHECK_STATE {0 , CHECK_STATE_HEADER };enum LINE_STATUS {0 , LINE_BAD, LINE_OPEN };enum HTTP_CODE { FORBIDDEN_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION }; static const char *szret[] = { "I get a correct result\n" , "Something wrong\n" };LINE_STATUS parse_line ( char *buffer, int &checked_index, int &read_index ) { char temp; for ( ; checked_index < read_index; ++checked_index ) { temp = buffer[checked_index]; if ( temp == '\r' ) { if ( ( checked_index + 1 ) == read_index ) { return LINE_OPEN; } else if ( buffer[checked_index+1 ] == '\n' ) { buffer[checked_index++] = '\0' ; bffer[checked_index++] = '\0' ; return LINE_OK; } return LINE_BAD; } else if ( temp == '\n' ) { if ( (checked_index > 1 ) && buffer[checked_index-1 ] == 'r' ) { buffer[checked_index-1 ] = '\0' ; buffer[checked_index++] = '\0' ; return LINE_OK; } return LINE_BAD; } } return LINE_OPEN; } HTTP_CODE parse_requestline ( char *temp, CHECK_STATE &checkstate) { char *url = strpbrk ( temp, " \t" ); if ( !url ) { return BAD_REQUEST; } *url++ = '\0' ; char *method = temp; if ( strcasecmp( method, "GET" ) == 0 ) { printf ( "The requese method is GET\n" ); } else { return BAD_REQUEST; } url+= strspn ( url, " \t" ) ; char *version = strpbrk ( url, " \t" ); if ( !version ) { return BAD_REQUEST; } *version++ = '\0' ; version += strspn ( version, " \t" ); if ( strcasecmp( version, "HTTP/1.1" ) != 0 ) { return BAD_REQUEST; } if ( strncasecmp( url, "http://" , 7 ) == 0 ) { url += 7 ; url = strchr ( url, '/' ); } if ( !url || url[0 ] != '/' ) { return BAD_REQUEST; } printf ( "The request URL is : %s\n" , url ); checkstate = CHECK_STATE_HEADER; return NO_REQUEST; } HTTP_CODE parse_header ( char *temp ) { if ( temp[0 ] == '\0' ) { return GET_REQUEST; } else if ( strncasecmp( temp, "Host:" , 5 ) == 0 ) { temp += 5 ; temp += strspn ( temp, " \t" ); printf ( "the request host is: %s\n" , temp ); } else { printf ( "I can't handle this header\n" ); } return NO_REQUEST; } HTTP_CODE parse_content ( char *buffer, int &checked_index, CHECK_STATE &checkstate, int &read_index, int &start_line ) { LINE_STATUS linestatus = LINE_OK; HTTP_CODE retcode = NO_REQUEST; while ( (linestatus = parse_line( buffer, checked_index, read_index)) == LINE_OK ) { char *temp = buffer + start_line; start_line = checked_index; switch ( checkstate ) { case CHECK_STATE_REQUESTLINE: { retcode = parse_requestline( temp, checkstate ); if ( retcode == BAD_REQUEST ) { return BAD_REQUEST; } break ; } case CHECK_STATE: { retcode = parse_header( temp ); if ( retcode == BAD_REQUEST ) { return BAD_REQUEST; } else if ( retcode == GET_REQUEST ) { return GET_REQUEST; } break ; } default : { return INTERNAL_ERROR; } } } if ( linestatus == LINE_OPEN ) { return NO_REQUEST; } else { return BAD_REQUEST; } } int main ( int argc, char *argv[] ) { if ( argc <= 2 ) { printf ( "usage: ... \n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi( argv[2 ] ); struct sockaddr_in address ; bzero( &address, sizeof ( address ) ); address.sin_family = AF_INET; address.sin_port = htons( port ); inet_pton( AF_INET, ip, &address.sin_addr ); int listenfd = socket( AF_INET, SOCK_STREAM, 0 ); assert( listenfd >= 0 ); int ret = bind( listenfd, (struct sockaddr*)&address, sizeof ( address ) ); assert( ret != -1 ); ret = listen( listenfd, 5 ); assert( ret != -1 ); struct sockaddr_in client ; socklen_t client_len = sizeof ( client ); int fd = accept( listenfd, (struct sockaddr*)&client, &client_len ); if ( fd < 0 ) { printf ( "errno is: %d\n" , errno ); } else { char buffer[BUFFER_SIZE]; memset ( buffer, '\0' , BUFFER_SIZE ); int data_read = 0 ; int read_index = 0 ; int checked_index = 0 ; int start_line = 0 ; CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE; while (1 ) { data_read = recv( fd, buffer+read_index, BUFFER_SIZE-read_index, 0 ); if ( data_read == -1 ) { printf ( "reading failed\n" ); break ; } else if ( data_read == 0 ) { printf ( "remote clinet has closed the connection\n" ); break ; } read_index += data_read; HTTP_CODE result = parse_content( buffer, checked_index, checkstate, read_index, start_line ); if ( reulst == NO_REQUEST ) { continue ; } else if ( result == GET_REQUEST ) { send( fd, szret[0 ], strlen ( szret[0 ] ), 0 ); break ; } else { send( fd, szret[1 ], strlen ( szret[1 ]), 0 ); break ; } } close( fd ); } close( listenfd ); return 0 ; }
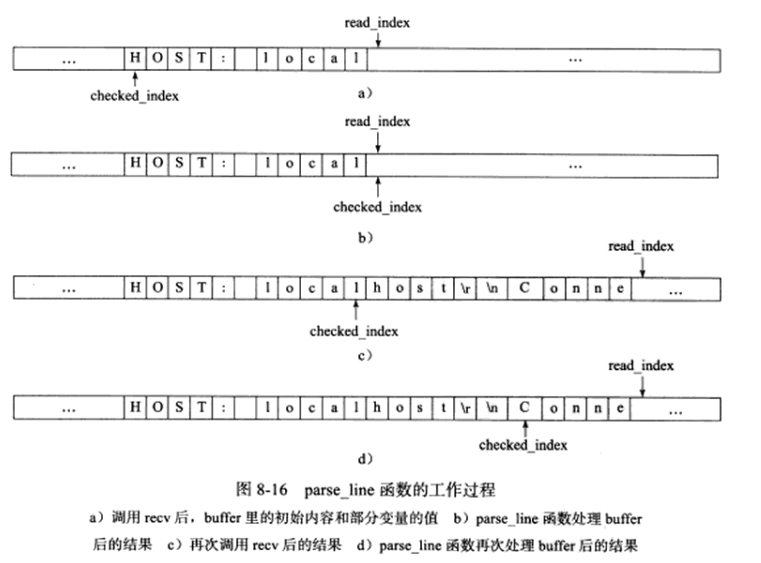
该代码中的两个有限状态机分别称为主状态机和从状态机,它们之间的关系:主状态机在内部调用从状态机。从状态机的状态及状态转移过程如下:
简单来说,该状态机的工作流程,recv收到数据后,调用parse_content函数(主状态机)来分析读入的数据,parse函数首先调用parse_line函数(从状态机)来获取一个完整的行。parseline函数的工作流程,如下图所示:
8.7 提高服务器性能的其他建议 讨论从编程的角度来确保服务器的性能。
a) 池
假设在服务器的硬件资源充分的情况下,提高服务器性能的一个直接的方式即是空间换时间,即”浪费”服务器的硬件资源,以换取其运行效率。这就是池的概念。简单来说,池就是将一些需要用到的资源提前分配创建好,用的时候直接从其中取资源比动态分配资源的速度要快得多,处理完后,将资源放回池中。
根据不同的资源类型,池可分为多种,常见的有内存池,进程池,线程池和连接池。
内存池通常用于socket的接受缓存和发送缓存。预先分配一个大小足够的缓冲区。
线程池和进程池,当我们需要一个工作进程/线程来处理客户请求时,可直接从池中取一个实体,而无需调用fork或pthread_create来创建。
连接池通常用于服务器或服务器集群的内部永久连接。
b) 上下文切换和锁
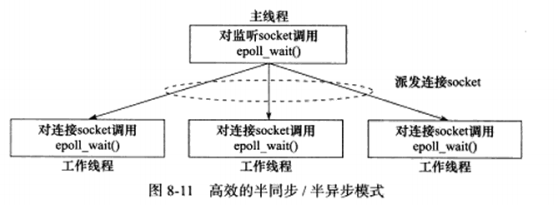
并发程序必须考虑上下文切换问题,即进程切换或线程切换导致的系统开销。即使是I/O密集型的服务器,也不应该使用过多的工作线程,否则线程间的切换将占用大量的CPU时间。因此,为每个客户连接都创建一个工作线程的服务器是不可取的。图8-11的模式是一种比较合理的解决方案。
另一个问题是对共享资源的加锁保护。锁通常被认为是导致服务器效率低下的一个因素,因为它引入的代码不处理任何业务逻辑,而且需要访问内核资源。如果服务器必须使用锁,考虑减小锁的粒度,比如使用读写锁。当所有工作线程都只读取一块共享内存的内容时,读写锁并不会增加额外的开销,只有当其中一个工作线程需要写这块内存时,才去上锁。
c) 数据复制
高性能服务器应该避免不必要的数据复制,尤其是当数据复制发生在用户和内核之间。比如ftp服务器,无需把目标文件的内容完整地读入到应用程序缓冲区中并调用send函数发送,而是可用”零拷贝”的sendfile函数直接发送。
此外,用户代码内部的数据复制也是应该避免的。比如,两个工作进程之间需要传递大量的数时,我们应该考虑使用共享内存在他们之间直接共享这些数据,而不是使用管道或消息队列来传递。
第9章 I/O复用 I/O复用使得程序能同时监听多个文件描述符,通常网络程序在下列情况下需要使用I/O复用功能:
客户端程序要同时处理多个socket。比如本章将讨论的非阻塞connect。
客户端程序要同时处理用户输入和网络连接。比如本章讨论的聊天室程序。
TCP服务器要同时处理监听socket和连接socket。
服务器要同时处理TCP请求和UDP请求。比如本章讨论的回射服务器。
服务器要同时监听多个端口,或者处理多种服务器。比如本章讨论的xinetd服务器。
Linux下实现I/O复用的系统调用主要有select,poll和epoll。
9.1 select系统调用 a) selectAPI
select系统调用的原型如下:
1 2 3 #include <sys/select.h> int select (int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout) ;
nfds参数指定被监听的文件描述符总数,通常被设置为select监听的所有描述符中的最大值加以。
readfds,exceptfds,writefds分别指向可读,异常和可写对应的文件描述符集合。fd_set结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include <typesizes.h> #define __fD_SETSIZE 1024 #include <sys/select.h> #define FD_SETSIZE __FD_SETSIZE typedef long in __fd_mask;#undef __NFDBITS #define __NFDBITS ( 8 * (int) sizeof (__fd_mask ) ) typedef struct {#ifdef __USE_XOPEN __fd_mask fds_bits[ __FD_SETSIZE / __NFDBITS ]; #define __FDS_BITS(set) ((set)->fds_bits) #else __Fd_mask __fds_bits[ __FD_SETSIZE / __NFDBITS ]; #define __FDS_BITS(set) ((set)->__fds_bits) #endif } fd_set;
使用如下一系列宏来访问fd_set结构体中的位:
1 2 3 4 5 #include <sys/select.h> FD_ZERO(fd_set *fdset); FD_SET(int fd, fd_set *fdset); FD_CLR(int fd, fd_set *fdset); int FD_ISSET (int fd, fd_set *fdset) ;
timeout参数设置超时时间:
1 2 3 4 struct timeval { long tv_sec; long tv_usec; };
select成功时返回就绪文件描述符的总数。
b) 文件描述符就绪条件
在网络编程中,下列情况下socket可读:
socket内核接受缓存区中的字节数大于或等于其低水位标记SO_RCVLOWAT。此时可以无阻塞地读该socket,且读操作返回的字节数大于0。
socket通信的对方关闭连接。此时读操作返回0。
监听socket上有新的连接请求。
socket上有未处理的错误。此时可以用getsockopt来读取和清除该错误。
下列情况下socket可写:
socket内核发送缓存区中的可用字节数大于或等于其低水位标记SO_SNDLOWAT。此时可用无阻塞的写该socket,且写操作的字节数大于0。
socket的写操作被关闭。对写操作被关闭的socket执行写操作将触发一个SIGPIPE信号。
socket使用非阻塞connect连接成功或者失败之后。
socket上有未处理的错误。此时可以用getsockopt来读取和清除该错误。
网络程序中,select能处理的异常情况只有一种:socket上接收到带外数据。下节将详细讨论。
c) 处理带外数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 //同时接受普通数据和带外数据 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> int main( int argc, char *argv[] ) { if ( argc <= 2 ) { printf( "usage: ... " ); return 1; } const char *ip = argv[1]; int port = atoi( argv[2] ); int ret = 0; struct sockaddr_in address; bzero( &address, sizeof( address ) ); address.sin_family = AF_INET; address.sin_port = htons( port ); inet_pton( AF_INET, ip, &address.sin_addr ); int listenfd = socket( AF_INET, SOCK_STREAM, 0 ); assert( listenfd >= 0 ); ret = bind( listenfd, (struct sockaddr*)&address, sizeof( address ) ); assert( ret != -1 ); ret = listen( listenfd, 5 ); assert( ret != -1 ); struct sockaddr client; socklen_t client_len = sizeof( client ); int connfd = accept( listenfd, (struct sockaddr*)&clinet, &client_len ); if ( connfd < 0 ) { printf( "errno is %d\n", errno ); close( listenfd ); } char buf[1024]; fd_set read_fds; fd_set exception_fds; FD_ZERO( &read_fds ); FD_ZERO( &exception_fds ); while (1) { memset( buf, '\0', sizeof(buf) ); //每次调用select前都需要重新在read_fds和exception_fds中设置文件描述符 FD_SET( connfd, &read_fds ); FD_SET( connfd, &exception_fds ); ret = select( connfd+1, &read_fds, NULL, &exception_fds, NULL ); if ( ret < 0 ) { printf( "selection failure\n" ); break; } //对于可读事件,采用普通的recv函数读取数据 if ( FD_ISSET( connfd, &read_fds ) ) { ret = recv( connfd, buf, sizeof(buf)-1, 0 ); if (ret <= 0) { break; } printf( "get %d bytes of normal data: %s\n", ret, buf ); } //对于异常事件,采用带MSG_OBB标志的recv函数读取带外数据 else if ( FD_ISSET( connfd, &exception_fds ) ) { ret = recv( connfd, buf, sizeof(buf)-1. MSG_OBB ); if ( ret <= 0 ) { break; } printf( "get %d bytes of obb data: %s\n", ret, buf ); } } close( connfd ); close( listenfd ); return 0; }
9.2 poll系统调用 poll系统调用与selec类似,也是指定时间内轮询一定数量的文件描述符:
1 2 #include <poll.h> int poll (struct pollfd *fds, nfds_t nfds, int timeout) ;
pollfd参数即select三种事件集合的综合,采用一个结构体,定义如下:
1 2 3 4 5 struct pollfd { int fd; short events; short revents; };
fd指定文件描述符,evets成员告诉poll监听fd上的哪些事件,它是一系列的按位或,revetns由内核修改,通知应用程序fd上实际发生了哪些事件。poll支持的事件类型如下表:
事件
描述
是否可作为输入
是否可作为输出
POLLIN
数据(包括普通数据和优先数据)可读
是
是
POLLRDNORM
普通数据可读
是
是
POLLRDBAND
优先级带数据可读(Linux不支持)
是
是
POLLPRI
高优先级数据可读,比如TCP带外数据
是
是
POLLOUT
数据(包括普通数据和优先数据)可写
是
是
POLLWRNORM
普通数据可写
是
是
POLLWRBAND
优先级带数据可写
是
是
POLLRDHUP
TCP连接被对方关闭,或者对方关闭了写操作。他由GUN引入
是
是
POLLER
错误
否
是
POLLHUP
挂起。比如管道的写端被关闭后,读描述上将收到POLLHUP事件
否
是
POLLNVAL
文件描述符没有打开
否
是
nfds参数指定被监听事件集合的fds的大小
timeout参数指定超时值
9.3 epoll系列系统调用 a) 内核事件表
epoll把用户关心的文件描述符上的事件放在内核的一个事件表中,从而无需像select和poll那样每次调用都要重复传入文件描述符集或事件集。但epoll需要一个额外的文件描述符,来唯一标识内核中的这个事件表,该文件描述符使用如下函数创建:
1 2 #include <sys/epoll.h> int epoll_create (int size) ;
size参数现在不起作用,仅作为给内核的一个提示,告诉他事件表需要多大。该函数返回的文件描述符将所用与其他epoll系统调用的第一个参数,以指定要访问的内核事件表。
下面的函数用来操作epoll的内核事件表:
1 2 #include <sys/epoll.h> int epoll_ctl (int epfd, int op, int fd, struct epoll_event *evnet) ;
fd参数为操作的描述符,op参数指定操作类型,类型如下三种:
EPOLL_CTL_ADD,往事件表中注册fd上的事件。
EPOLL_CTL_MOD,修改fd上的注册事件。
EPOLL_CTL_DEL,删除fd上的注册事件。
event参数指定事件,它是epoll_event结构指针类型。定义如下:
1 2 3 4 struct epoll_event { __uint32_t events; epoll_data_t data; };
data成员用于存储用户数据,其类型定义如下:
1 2 3 4 5 6 typedef union epoll_data { void *ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t ;
b) epoll_wait函数
epoll系列系统调用的主要接口函数:
1 2 #include <sys/epoll.h> int epoll_wait (int epfd, struct epoll_event *evetns, int maxevents, int timeout) ;
epoll_wait函数如果检测到事件,就将所有就绪的事件从内核事件表中复制到它的第二个参数events指向的数组中。这个数组只用于输出epoll_wait检测到的就绪事件,而不像select和Poll既用于传入,又用于输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int ret = poll(fds, MAX_EVENT_NUMBER, -1 );for (int i = 0 ; i<MAX_EVENT_NUMBER; ++i) { if (fds[i].revents & ) { int sockfd = fds[i],fd; } } int ret = epoll_wait(epollfd, evetns, MAX_EVENT_NUMBER, -1 );for (int i = 0 ; i<ret; i++) { int sockfd = evetns[i].data.fd; }
c) LT和ET模式
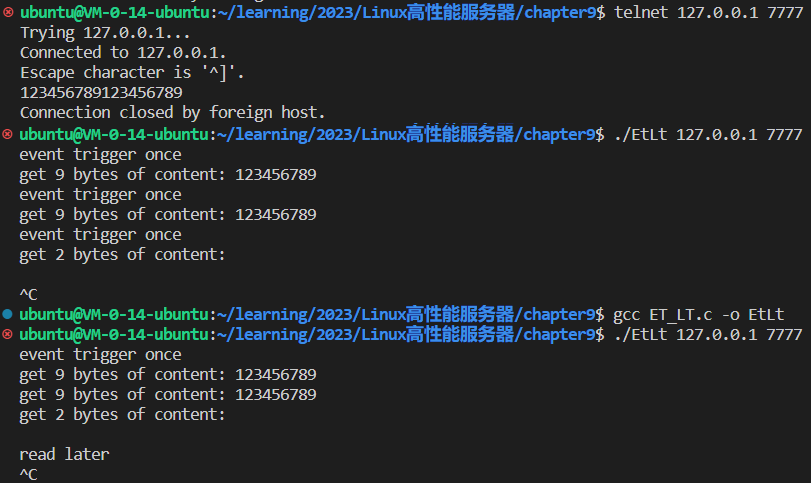
epoll对文件描述符的操作有两种模式: LT (Level Trigger, 电平触发)模式和 ET(Edge Trigger, 边沿触发)模式。LT模式是默认的工作模式,这种模式相当于一个效率较高的poll。当注册事件EPOLLET时,epoll将以ET模式来操作,ET模式是epoll的高效工作模式。
LT:epoll_wait检测到其上有事件发生并将此事件通知应用程序后,应用程序可以不立即处理该事件。这样,下次调用epoll_wait时,epoll_wait还会再次向应用程序通告此事件,直到该事件被处理。
ET:应用程序必须立即处理,因为后续的epoll_wait调用将不再向应用程序通知这一事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <unistd.h> #include <stdio.h> #include <errno.h> #include <fcntl.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/types.h> #include <pthread.h> #define MAX_EVENT_NUMBER 1024 #define BUFFER_SIZE 10 #define true 1 #define false 0 typedef int bool ;int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd (int epollfd, int fd, bool enable_et) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN; if (enable_et) { event.events |= EPOLLET; } epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } void Lt (struct epoll_event *events, int number, int epollfd, int listenfd) { char buf[BUFFER_SIZE]; for (int i=0 ; i<number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address ; socklen_t client_addrlen = sizeof (client_address); int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlen); addfd(epollfd, connfd, false ); } else if (events[i].events & EPOLLIN) { printf ("event trigger once\n" ); memset (buf, '\0' , BUFFER_SIZE); int ret = recv(sockfd, buf, BUFFER_SIZE-1 , 0 ); if (ret <= 0 ) { close(sockfd); continue ; } printf ("get %d bytes of content: %s\n" , ret ,buf); } else { printf ("something else happend\n" ); } } } void Et (struct epoll_event* events, int number, int epollfd, int listenfd) { char buf[BUFFER_SIZE]; for (int i=0 ; i<number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address ; socklen_t client_addrlen = sizeof (client_address); int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlen); addfd(epollfd, connfd, true ); } else if (events[i].events & EPOLLIN) { printf ("event trigger once\n" ); while (1 ) { memset (buf, '\0' , BUFFER_SIZE); int ret = recv(sockfd, buf, BUFFER_SIZE-1 , 0 ); if (ret < 0 ) { if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { printf ("read later\n" ); break ; } close(sockfd); break ; } else if (ret == 0 ) { close(sockfd); } else { printf ("get %d bytes of content: %s\n" , ret, buf); } } } else { printf ("something else happend\n" ); } } } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: ip_address port_number\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); int opt = 1 ; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); ret = bind(listenfd, (struct sockaddr*)&address, sizeof (address)); assert(ret != -1 ); ret = listen(listenfd, 5 ); assert(ret != -1 ); struct epoll_event events [MAX_EVENT_NUMBER ]; int epollfd = epoll_create(5 ); assert(epollfd != -1 ); addfd(epollfd, listenfd, true ); while (1 ) { int ret = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1 ); if (ret < 0 ) { printf ("epolll failure\n" ); break ; } Et(events, ret, epollfd, listenfd); } close(listenfd); return 0 ; }
d) EPOLLONESHOT事件
即使我们使用ET模式,一个socket上的某个事件还是可能被多次触发。在并发中这会导致一个问题,比如一个线程读完某个socket上的数据开始处理这些数据,而在数据处理过程中,socket上又有新数据可读,EPOLLIN再次触发,此时另一个线程被唤醒来读取这些数据。导致出现了两个线程同时操作一个socket的局面。使用epoll的EPOLLONESHOT事件解决该情况。
对于注册了EPOLLONESHOT事件的文件描述符,操作系统最多触发其上注册的一个可读,可写或异常事件,且只触发一次,除非我们使用epoll_ctl函数重置该文件描述符上注册的EPOLLONESHOT事件。
有点像上锁(。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> #include <sys/epoll.h> #include <pthread.h> #define MAX_EVENT_NUMBER 1024 #define BUFFER_SIZE 1024 #define true 1 #define false 0 typedef int bool ;struct fds { int epollfd; int sockfd; }; int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd (int epollfd, int fd, bool oneshot) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; if (oneshot) { event.events |= EPOLLONESHOT; } epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } void reset_oneshot (int epollfd, int fd) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN | EPOLLET | EPOLLONESHOT; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); } void *worker (void *arg) { int sockfd = ((fds*)arg)->sockfd; int epollfd = ((fds*)arg)->epollfd; printf ("start new thread to receive data on fd: %d\n" , sockfd); char buf[BUFFER_SIZE]; memset (buf, '\0' , BUFFER_SIZE); while (1 ) { int ret = recv(sockfd, buf, BUFFER_SIZE-1 , 0 ); if (ret == 0 ) { close(sockfd); printf ("foreinter closed the connection\n" ); break ; } else if (ret < 0 ) { if (errno == EAGAIN) { reset_oneshot(epollfd, sockfd); printf ("read later\n" ); break ; } } else { printf ("get content: %s\n" , buf); sleep(5 ); } } printf ("end thread receiving data on fd:\n" , sockfd); } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); int opt = 1 ; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); ret = bind(listenfd, (struct sockaddr*)&address, sizeof (address)); assert(ret != -1 ); ret = listen(listenfd, 5 ); assert(ret != -1 ); strcut epoll_event events[MAX_EVENT_NUMBER]; int epollfd = epoll_create(5 ); assert(epollfd != -1 ); addfd(epollfd, listenfd, false ); while (1 ) { int ret = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1 ); if (ret < 0 ) { printf ("epoll failure\n" ); break ; } for (int i = 0 ; i<ret; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address ; socklen_t client_addrlen = sizeof (client_address); int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlen); addfd(epollfd, connfd, true ); } else if (events[i].events & EPOLLIN) { pthread_t thread; fds fds_for_new_worker; fds_for_new_worker.epollfd = epollfd; fds_for_new_worker.sockfd = sockfd; pthread_create(&thread, NULL , worker, (void *)&fds_for_new_worker); } else { printf ("something else happend\n" ); } } } close(listenfd); return 0 ; }
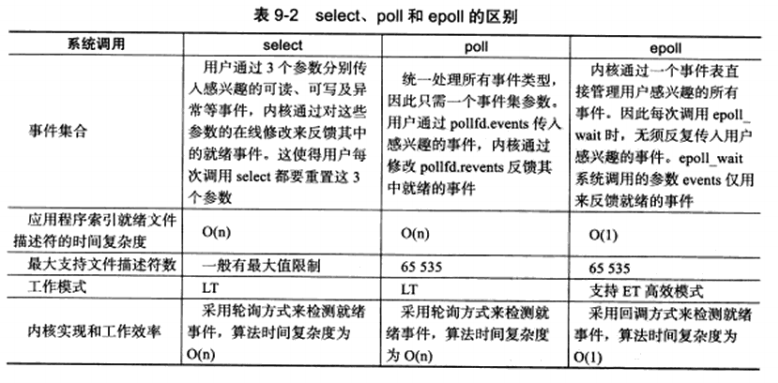
9.4 三组I/O复用函数的比较 事件集合不同,select通过三个事件集来监听,并且内核通过对其的修改来反馈结果,所以每次调用都需要重置这3个参数,poll将三个统一为一个,将输入和输出分为event和revent分离,epoll则内核将输出传出,无需反复传入用户需要监听的事件。
工作模式,select和poll只支持LT模式,epoll支持ET和LT。
内核实现和效率,select和poll采用轮询方式检测就绪事件,时间复杂度O(n);epoll通过回调方式来检测,时间复杂度O(1)。
9.5 I/O复用的高级应用一: 非阻塞connect
上述文描述了connect出错时的一种errno值:EINPROGRESS。这种错误发生在对非阻塞的socket调用connect,而连接又没有立即建立时。在这种情况下,可以调用select,poll等函数来监听这个连接失败的socket上的可写事件。当select,poll函数返回后,再利用getsockopt来读取错误码并清除该socket上的错误。如果错误码是0表示连接建立成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <stdlib.h> #include <time.h> #include <errno.h> #include <fcntl.h> #include <unistd.h> #include <sys/ioctl.h> #include <string.h> #define BUFFER_SIZE 1023 int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } int unblock_connect (const char *ip, int port, int time) { int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int sockfd = socket(AF_INET, SOCK_STREAM, 0 ); int fdopt = setnonblocking(sockfd); ret = connect(sockfd, (struct sockaddr*)&address, sizeof (address)); if (ret == 0 ) { printf ("connect with server immediately\n" ); fcntl(sockfd, F_SETFL, fdopt); return sockfd; } else if (errno != EINPROGRESS) { printf ("unblock connect not support\n" ); return -1 ; } fd_set readfds; fd_set writefds; struct timeval timeout ; FD_ZERO(&readfds); FD_SET(sockfd, &writefds); timeout.tv_sec = time; timeout.tv_usec = 0 ; ret = select(sockfd+1 , NULL , &writefds, NULL , &timeout); if (ret <= 0 ) { printf ("connection time out\n" ); close(sockfd); return -1 ; } if (!FD_ISSET(sockfd, &writefds)) { printf ("no event on sockfd found\n" ); close(sockfd); return -1 ; } int error = 0 ; socklen_t length = sizeof (error); if (getsockopt(sockfd, SOL_SOCKET, SO_ERROR, &error, &legnth) < 0 ) { printf ("get socket option failed\n" ); close(sockfd); return -1 ; } if (error != 0 ) { printf ("connection failed afeter select with the error: %d\n" , error); close(sockfd); return -1 ; } printf ("connection ready after select with the socket: %d\n" , sockfd); fcntl(sockfd, F_SETFL, fdopt); return sockfd; } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int sockfd = unblock_connect(ip, port, 10 ); if (sockfd < 0 ) { return 1 ; } close(sockfd); return 0 ; }
但该方法存在移植性问题。首先,非阻塞的socket可能导致connect失败。其次select对处于EINPROGRESS状态下的socket可能不起作用。以及,出错的socket,getsockopt返回值不一,有的为-1,有的为0。
9.6 I/O复用的高级应用二: 聊天室程序 以poll实现一个简单的聊天室程序。阐述如何使用I/O复用技术来同时处理网络连接和用户输入。它分为客户端和服务端两个部分。
客户端:一是从标准输入终端读入用户数据,并将用户数据发送至服务器;二是往标准输出终端打印服务器发送给它的数据。
服务器:接受用户数据,并把客户数据发送给每一个登录到该服务器上的客户端,数据发送者除外。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 #define _GNU_SOURCE 1 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <string.h> #include <unistd.h> #include <stdlib.h> #include <poll.h> #include <fcntl.h> #define BUFFER_SIZE 64 int main (int argc, char *argv[]) { if (argc <=2 ){ printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); struct sockaddr_in server_address ; bzero(&server_address, sizeof (server_address)); server_address.sin_family = AF_INET; server_address.sin_port = htons(port); inet_pton(AF_INET, ip, &server_address.sin_addr); int sockfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(sockfd >= 0 ); if (connect(sockfd, (struct sockaddr*)&server_address, sizeof (server_address)) < 0 ) { printf ("connection failed\n" ); close(sockfd); return 1 ; } struct pollfd fds [2]; fds[0 ].fd = 0 ; fds[0 ].events = POLLIN; fds[0 ].revents = 0 ; fds[1 ].fd = sockfd; fds[1 ].events = POLLIN; fds[1 ].revents = 0 ; char read_buf[BUFFER_SIZE]; int pipefd[2 ]; int ret = pipe(pipefd); assert(ret != -1 ); while (1 ) { ret = poll(fds, 2 , -1 ); if (ret < 0 ) { printf ("poll failure\n" ); break ; } if (fds[1 ].revents & POLLRDHUP) { printf ("server close the connection\n" ); break ; } else if (fds[1 ].revents & POLLIN) { memset (read_buf, '\0' , BUFFER_SIZE); recv(fds[1 ].fd, read_buf, BUFFER_SIZE-1 , 0 ); printf ("%s\n" ,read_buf); } if (fds[0 ].revents & POLLIN) { ret = splice(0 , NULL , pipefd[1 ], NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE); ret = splice(pipefd[0 ], NULL , sockfd, NULL , 32768 , SPLICE_F_MORE | SPLICE_F_MOVE); } } close(sockfd); return 0 ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 #define _GNU_SOURCE 1 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <fcntl.h> #include <stdlib.h> #include <poll.h> #define USER_LIMIT 5 #define BUFFER_SIZE 64 #define FD_LIMIT 65535 struct client_data { sockaddr_in address; char *write_buf; char buf[BUFFER_SIZE]; }; int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_GETFL, new_option); return old_option; } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); int opt = 1 ; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); ret = bind(listenfd, (struct sockaddr*)&address, sizeof (address)); assert(ret != -1 ); ret = listen(listenfd, 5 ); assert(ret != -1 ); struct client_data *users =struct client_data*)malloc (FD_LIMIT * sizeof (struct client_data)); pollfd fds[USER_LIMIT+1 ]; int user_counter = 0 ; for (int i = 1 ; i<= USER_LIMIT; i++) { fds[i].fd = -1 ; fds[i].events = 0 ; } fds[0 ].fd = listenfd; fds[0 ].events = POLLIN | POLLERR; fds[0 ].revents = 0 ; while (1 ) { ret = poll(fds, user_counter++, -1 ); if (ret < 0 ) { printf ("poll failure\n" ); breka; } for (int i=0 ; i< user_counter+1 ; i++) { if ((fds[i].fd == listenfd) && (fds[i].revents & POLLIN)) { struct sockaddr_in client_address ; socklen_t client_addrlen = sizeof (client_address); int connfd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlen); if (connfd < 0 ) { printf ("errno is: %d\n" , errno); continue ; } if (user_counter >= USER_LIMIT) { const char *info = "too many users\n" ; printf ("%s" , info); send(connfd, info ,strlen (info), 0 ); close(connfd); contniue; } user_counter++; users[connfd].address = client_address; setnonblocking(connfd); fds[user_counter].fd = connfd; fds[user_counter].events = POLLIN | POLLRDHUP | POLLERR; fds[user_counter].revents = 0 ; printf ("comes a new user, now have %d users\n" , user_counter); } else if (fds[i].revents & POLLERR) { printf ("get an error from %d\n" , fds[i].fd); char errors[100 ]; memset (errors, '\0' , 100 ); socklen_t legnth = sizeof (errors); if (getsockopt(fds[i].fd, SOL_SOCKET, SO_ERROR, &errors, &length) < 0 ) { printf ("get socket option failed\n" ); } contniue; } else if (fds[i].revents & POLLRDHUP) { users[fds[i].fd] = users[fds[user_counter].fd]; close(fds[i].fd); fds[i] = fds[user_counter]; i--; user_counter--; printf ("a client left\n" ); } else if (fds[i].revents & POLLIN) { int connfd = fds[i].fd; memset (user[connfd],buf, '\0' , BUFFER_SIZE); ret = recv(connfd, users[connfd].buf, BUFFER_SIZE-1 , 0 ); printf ("get %d bytes of client data %s from %d\n" , ret, user[connfd].buf, connfd); if (ret < 0 ) { if (errno != EAGAIN) { close(connfd); user[fds[i].fd] = user[fds[user_counter].fd]; fds[i] = fds[user_counter]; i--; user_counter--; } } else if (ret == 0 ) { } else { for (int j=1 ; j<=user_counter; j++) { if (fds[j].fd == connfd) { contniue; } fds[j].events |= ~POLLIN; fds[j].events |= POLLOUT; users[fds[j].fd].write_buf = users[connfd].buf; } } } else if (fds[i].revents & POLLOUT) { int connfd = fds[i].fd; if (!users[connfd],write_buf) { continue ; } ret = send(connfd, users[connfd].write_buf, strlen (users[connfd].write_buf), 0 ); users[connfd].write_buf = NULL ; fds[i].events |= ~POLLOUT; fds[i].events |= POLLIN; } } } free (users); close(listenfd); return 0 ; }
9.7 I/O复用的高级应用三: 同时处理TCP和UDP服务 同时处理多个端口。下示代码所示的回射服务器能够同时处理一个端口上的TCP和UDP请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 #include <sys/types.h> #include <sys/socekt.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> #include <sys/epoll.h> #include <pthread.h> #define MAX_EVENT_NUMBER 1024 #define TCP_BUFFER_SIZE 512 #define UDP_BUFFER_SIZE 1024 int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd (int epollfd, int fd) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); int opt = 1 ; setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof (opt)); ret = bind(listenfd, (struct sockaddr*)&address, sizeof (address)); assert(ret != -1 ); ret = listen(listenfd, 5 ); assert(ret != -1 ); bzero(&address, sizeof (address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = htons(port); int updfd = socket(AF_INET, SOCK_DGRAM, 0 ); assert(udpfd >= 0 ); ret = bind(updfd, (struct sockaddr*)&address, sizeof (address)); assert(ret != -1 ); struct epoll_event evnets [MAX_EVENT_NUMBER ]; int epollfd = epoll_create(5 ); assert(epollfd != -1 ); addfd(epollfd, listenfd); addfd(epollfd, updfd); while (1 ) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1 ); if (number < 0 ) { printf ("epoll failed\n" ); break ; } for (int i=0 ; i<number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client ; socklen_t client_len = sizeof (client); int connfd = accept(listenfd, (struct sockaddr*)&client, &client_len); addfd(epollfd, connfd); } else if (sockfd == updfd) { char buf[UDP_BUFFER_SIZE]; memset (buf, '\0' , UDP_BUFFER_SIZE); struct sockaddr_in client_address ; socklen_t client_addrlen = sizeof (client_address); ret = recvfrom(updfd, buf, UDP_BUFFER_SIZE-1 , 0 , (struct sockaddr*)&client_address, &client_addrlen); if (ret >0 ) { sendto(updfd, buf, UDP_BUFFER_SIZE-1 , 0 , (struct sockaddr*)&client_address, &client_addrlen); } } else if (events[i].events & EPOLLIN) { char buf[TCP_BUFFER_SIZE]; while (1 ) { memset (buf, '\0' , TCP_BUFFER_SIZE-1 , 0 ); if (ret < 0 ) { if ((errno == EAGAIN) || (errno == EWOULDBLOCK)) { break ; } close(sockfd); break ; } else if (ret == 0 ) { close(sockfd); } else { send(sockfd, buf, ret, 0 ); } } } else { printf ("something else happend\n" ); } } } close(listenfd); return 0 ; }
9.8 超级服务xinetd Linux因特网服务inetd是超级服务。它同时管理着多个子服务,即监听多个端口。现在Linux系统上使用的inetd服务程序通常是其升级版本xinetd。
a) xinetd配置文件
xinetd采用/etc/xinetd.conf主配置文件和/etc/xinetd.d目录下的子配置文件来管理所有服务器。主配置文件是通用选项,这些选项将被所有子配置文件继承。但子配置文件可覆盖这些选项。子配置文件用于设置一个自服务的参数,如telnet字符的配置文件典型内容如下:
b) xinetd工作流程
xinetd管理的子服务中的标准服务,如日期服务daytime,回射服务echo直接在内部处理这些事务,有的子服务则需要调用外部服务器来处理,xinetd通过调用fork和exec函数来加载这些服务器程序,如telnet,ftp服务。以telnet服务来探讨xinetd的工作流程。
第10章 信号 10.1 Linux信号概述 a) 发送信号
kill函数,定义如下:
1 2 3 #include <sys/types.h> #include <signal.h> int kill (pid_t pid, int sig) ;
pid参数,取值及含义如下表:
pid参数
含义
pid > 0
信号发送给PID为pid的进程
pid = 0
信号发送给本进程组内的其他进程
pid = -1
信号发送给除init进程外的所有进程,但发送者需要拥有对目标进程发送信号的权限
pid < -1
信号发送给组ID为-pid的进程组中的所有成员
Linux定义的信号值都大于0,如果sig取值为0,kill函数不发送任何信号。但可以用来检测目标进程或进程组是否存在,因为检查工作在发送之前执行。
失败时返回的errno可能值如下表:
errno
含义
EINVAL
无效的信号
EPERM
该进程没有权限发送信号给任何一个目标进程
ESRCH
目标进程或进程组不存在
b) 信号处理方式
收到信号时,需要定义一个接收函数来处理信号,信号处理函数原型如下:
1 2 #include <signal.h> typedef void (*__sighandler_t ) (int ) ;
int参数用来指示信号类型。除自定义处理函数外,还定义了信号的两种其他处理方式–SIG_IGN和SIG_DEL
1 2 3 #include <bits/signum.h> #define SIG_DFL ((__sighandler_t)0) #define SIG_IGN ((__sighandler_t)1)
SIG_IGN表示忽略目标信号,SIG_DFL表示使用信号的默认处理方式:结束进程(Term),忽略信号(Ign),结束进程并生成核心转储文件(Core),暂停进程(Stop),以及继续进程(Cont)。
c) Linux信号
Linux可用的信号都定义在bits/signum.h头文件中。
后面重点介绍与网络编程关系紧密的几个信号:SIGHUP,SIGPIPE,SIGURG。以及SIGALRM,SIGCHLD。
d) 中断系统调用
如果程序执行处于阻塞状态的系统调用收到信号,默认情况下,系统调用将被中断,并且errno被设置为EINTR。可用使用sigaction函数为信号设置SA_RESTART标志,以自动重启被中断的系统调用。
10.2 信号函数 a) signal系统调用
为信号设置处理函数,signal函数:
1 2 #include <signal.h> _sighandler_t signal (int sig, _sighandler_t _handler) ;
sig参数指出要捕获的信号类型。_handler函数指针,指定信号sig的处理函数。
b) sigaction系统调用
简单来说signal的升级版本系统调用:
1 2 #include <signal.h> int sigaction (int sig, const struct sigaction *act, struct sigaction *ocat) ;
sig参数指出要捕获的信号,act参数指定新的信号处理方式,oact参数输出信号先前的处理方式。act的结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct sigaction {#ifdef __USE_POSIX199309 union { _sighandler_t sa_handler; void (*sa_sigaction)(int , siginfo_t *, void *); }_sigaction_handler; #define sa_handler __sigaction_handler.sa_handler; #define sa_sigaction __sigaction_handler_sa_sigaction #else _sighandler_t sa_handler; #endif _sigset_t sa_mask; int sa_flags; void (*sa_restorer)(void ); };
sa_handler指定处理函数,sa_sigaction好像是特殊处理,详细见APUE。sa_mask设置进程的信号掩码。sa_flags成员用于设置程序收到信号时的行为,可选值如下表:
sa_restorer成员已过时,不使用。
10.3 信号集 a) 信号集函数
Linux使用sigset_t表示一组信号,定义如下:
1 2 3 4 5 #include <bits/sigset.h> #define _SIGSET_NWORDS (1024 / (8 * sizeof(unsigned long int))) typedef struct { unsigned long int __val[_SIGSET_NWORDS]; }__sigset_t ;
由此可见,sigset_t实际是一个长整型数组,数组的每个元素的每一位表示一个信号,和fd_set类似。同样,提供了如下一组函数用来设置,修改,删除和查询信号集。
1 2 3 4 5 6 #include <signal.h> int sigemptyset (sigset_t *_set) ; int sigfillset (sigset_t *_set) ; int sig_addset (sigset_t *_set, int _signo) ; int sig_delset (sigset_t *_set, int _signo) ; int sigismemeber (_const sigset_t *set , int _signo) ;
b) 进程信号掩码
如下函数用于设置或查看进程的信号掩码:
1 2 #include <signal.h> int sigprocmask (int _how, _const sigset_t *_set, sigset_t *_oset) ;
_set指定新的信号掩码,_oset输出原来的信号掩码,how指定设置信号掩码的方式,可选值如下表:
_how参数
含义
SIG_BLOCK
新的进程信号掩码是当前值和_set指定信号集的并集
SIG_UNBLOCK
新的进程信号掩码是当前值和~_set信号集的交集,因此_set指定的信号不再被屏蔽
SIG_SETMASK
直接将进程信号的掩码设置为_set
如果set为NULL,进程信号掩码不变,此时可以利用_oset获取进程当前的信号掩码。
c) 被挂起的信号
设置信号掩码后,被屏蔽的信号将不再被进程接收。如果给进程发送一个被屏蔽的信号,操作系统将其设置为进程的一个被挂起的信号。如果取消对其的屏蔽,则他能被立即接收到,如下函数可获得进程当前被挂起的信号集:
1 2 #include <signal.h> int sigpending (sigset_t *set ) ;
set参数用于保存被挂起的信号集。
10.4 统一事件源 信号是一种异步事件:信号处理函数和程序的主循环是两条不同的执行路线。所以需要尽快的执行完处理函数,以确保信号不被屏蔽太久。
一种典型的解决方案是:把信号的主要处理逻辑放到程序的主循环中,当信号处理函数被触发时,它指示简单的通知主循环程序接收信号,并把信号值传递给主循环,主循环再根据接收到的信号值执行目标信号对应的逻辑代码。信号处理函数通常使用管道来讲信号传递给主循环:信号往管道的写端写入信号值,主循环从读端读出信号值。同时主循环通过I/O复用技术来监听读端文件描述符上的可读事件。
如此一来,信号事件就能和其他I/O事件一样被处理,即统一事件源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> #include <netinet/in.h> #include <assert.h> #include <stdio.h> #include <signal.h> #include <errno.h> #include <unistd.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> #include <sys/epoll.h> #include <pthread.h> #define true 1 #define false 0 #define MAX_EVENT_NUMBER 1024 static int pipefd[2 ];typedef int bool ;int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, new_option); return old_option; } void addfd (itn epollfd, int fd) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN || EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } void sig_handler (int sig) { int save_errno = errno; int msg = sig; send(pipefd[1 ], (char *)&msg, 1 , 0 ); errno = save_errno; } void addsig (int sig) { struct sigaction sa ; memset (&sa, '\0' , sizeof (sa)); sa.sa_handler = sig_handler; sa.sa_flags |= SA_RESTART; sigfillset(&sa.sa_mask); assert(sigaction(sig, &sa, NULL ) != -1 ); } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); int bind (listenfd, (struct sockaddr*)&address, sizeof (address)) ; if (ret == -1 ) { printf ("errno is %d\n" , errno); return 1 ; } ret = listen(listenfd, 5 ); assert(ret != -1 ); struct epoll_event evetns [MAX_EVENT_NUMBER ]; int epollfd = epoll_create(5 ); assert(epollfd != -1 ); addfd(epollfd, listenfd); ret = socketpair(AF_UNIX, SOCK_STREAM, 0 , pipefd); assert(ret != -1 ); setnonblocking(pipefd[1 ]); addfd(epollfd, pipefd[0 ]); addsig(SIGHUP); addsig(SIGCHLD); addsig(SIGTERM); addsig(SIGINT); bool stpo_server = false ; while (!stpo_server) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1 ); if ((number < 0 ) && (errno != EINTR)) { printf ("epoll failure\n" ); break ; } for (int i = 0 ; i<number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client ; socklen_t client_len = sizeof (client); int connfd = accept(listenfd, (struct sockaddr*)&client, &client_len); addfd(epollfd, connfd); } else if ((sockfd == pipefd[0 ]) && (evnets[i].events & EPOLLIN)) { int sig; char signals[1024 ]; ret = recv(pipefd[0 ], signals, sizeof (signals), 0 ); if (ret == -1 ) { continue ; } else if (ret == 0 ) { continue ; } else { for (int i = 0 ; i<ret; i++) { switch (signals[i]) { case SIGCHLD: case SIGHUP: { continue ; } case SIGTERM: case SIGINT: { stpo_server = true ; } } } } } else { } } } printf ("close fds\n" ); close(listenfd); close(pipefd[0 ]); close(pipefd[1 ]); return 0 ; }
10.5 网络编程相关信号 a) SIGHUP
当挂起进程的控制终端时,SIGHUP信号将被触发。对于没有控制中断的网络后台程序而言,它们通常利用SIGHUP信号来强制服务器重新读取配置文件,一个典型的例子是xinetd超级服务器程序。
b) SIGPIPE
默认情况下,往一个读端关闭的管道或socket连接中写数据讲引发SIGPIPE信号。默认处理为结束进程,所以我们需要捕获并处理该信号,至少忽略他。引起SIGPIPE信号的写操作讲设置errno为EPIPE。
可以使用send函数的MSG_NOSIGNAL标志来禁止写操作触发SIGPIPE信号。这种情况下,通过send函数反馈的errno值来判断管道或socket连接是否已关闭。
此外,可以利用I/O复用系统调用来检测管道和socket连接的读端是否已关闭。以poll为例,关闭时,写端文件描述符上的POLLHUP事件将触发。
c) SIGURG
内核通知带外数据到达的两种方法:一是前面介绍的I/O复用技术,借由select报告异常事件,二是使用SIGURG信号。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <stdio.h> #include <assert.h> #include <unistd.h> #include <errno.h> #include <stdlib.h> #include <string.h> #include <signal.h> #include <fcntl.h> #define BUFFER_SIZE 1024 static int connfd;void sig_urg (int sig) { int save_errno = errno; char buffer[BUFFER_SIZE]; memset (buffer, '\0' , BUFFER_SIZE); int ret = recv(connfd, buffer, BUFFER_SIZE-1 , MSG_OOB); printf ("got %d bytes of obb data '%s'\n" , ret, buffer); errno = save_errno; } void addsig (int sig, void (*sig_handler)(int )) { struct sigaction sa ; memset (&sa, '\0' , sizeof (sa)); sa.sa_handler = sig_handler; sa.sa_flags |= SA_RESTART; sigfillset(&sa.sa_mask); ASSERT(sigaciton(sig, &sa, NULL ) != -1 ); } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); int bind (listenfd, (struct sockaddr*)&address, sizeof (address)) ; if (ret == -1 ) { printf ("errno is %d\n" , errno); return 1 ; } ret = listen(listenfd, 5 ); assert(ret != -1 ); struct sockaddr_in client ; socklen_t client_len = sizeof (client); connfd = accept(listenfd, (sturct sockaddr*)&client, &client_len); if (connfd < 0 ) { printf ("errno is %d\n" , ernno); } else { addsig(SIGURG, sig_urg); fcntl(connfd, F_SETOWN, getpid()); char buffer[BUFFER_SIZE]; while (1 ) { memset (buffer, '\0' , BUFFER_SIZE); ret = recv(connfd, buffer, BUFFER_SIZE-1 , 0 ); if (ret <= 0 ) { break ; } printf ("got %d bytes of normal data '%s'\n" , ret, buffer); } close(connfd); } close(listenfd); return 0 ; }
第11章 定时器 本章主要讨论两种高效管理定时器的容器:时间轮和时间堆。在讨论如何组织定时器之前,首先介绍定时的方法。Linux提供了三种定时方法,它们是:
socket选项SO_RCMTIMEO和SO_SNDTIMEO。
SIGALRM信号。
I/O复用系统调用的超时参数。
11.1 socket选项SO_RCVTIMEO和SO_SNDTIMEO 这两个选项仅对与数据接收和发送相关的socket专用系统调用有效,包括send,sendmsg,recv,recvmsg,accpet和connect。
系统调用
有效选项
系统调用超时后的行为
send
SO_SNDTIMEO
返回-1,设置errno为EAGAIN或EWOULDBLOCK
sendmsg
SO_SNDTIMEO
返回-1,设置errno为EAGAIN或EWOULDBLOCK
recv
SO_RCVTIMEO
返回-1,设置errno为EAGAIN或EWOULDBLOCK
recvmsg
SO_RCVTIMEO
返回-1,设置errno为EAGAIN或EWOULDBLOCK
accept
SO_RCVTIMEO
返回-1,设置errno为EAGAIN或EWOULDBLOCK
connect
SO_SNDTIMEO
返回-1,设置errno为EINPROGRESS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include <sys/types.h> #include <sys/socket.h> #include <arpa/inet.h> #include <netinet/in.h> #include <stdlib.h> #include <errno.h> #include <stdio.h> #include <fcntl.h> #include <unistd.h> #include <string.h> #include <assert.h> int timeout_connect (const char *ip, int port, int time) { int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int sockfd = socekt(AF_INET, SOCK_STREAM, 0 ); assert(sockfd >= 0 ); struct timeval timeout ; timeout.tv_sec = time; timeout.tv_usec = 0 ; socklen_t len = sizeof (timeout); ret = setsockopt(sockfd, SOL_SOCKET, SO_SNDTIMEO, &timeout, len); assert(ret != -1 ); ret = connect(sockfd, (struct sockaddr*)&address, sizeof (address)); if (ret == -1 ) { if (errno == EINPROGREE) { printf ("connecting timeout, process timeout logic\n" ); return -1 ; } printf ("error occur when connecting to server\n" ); return -1 ; } return sockfd; } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int sockfd = timeout_connect(ip, port, 10 ); if (sockfd < 0 ){ return 1 ; } return 0 ; }
11.2 SIGALRM信号 由alarm和setitimer函数设hi的实时闹钟一旦超时,将触发SIGALRM信号。
本节通过一个示例–处理非活动连接,来介绍如何使用SIGALRM信号。首先给出一种简单的定时器容器实现–基于升序链表的定时器容器,并把应用到该示例。
a) 基于升序链表的定时器
定时器通常至少需要两个成员:超时时间和任务回调函数。以及可能包含回调函数执行时传入的参数,以及是否重启定时器等信息。
以链表作为容器来串联所有的定时器,则每个定时器还需要一个指向下一个定时器节点的指针。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 #ifdef LST_TIMER #define LST_TIMER #include <time.h> #define BUFFER_SIZE 64 class util_timer ;struct client_data { sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; util_timer *timer; }; class util_timer {public: util_timer(): prev(NULL ), next(NULL ) {} public: time_t expire; void (*cb_func)(client_data*); client_data *user_data; util_timer *prev; util_timer *next; }; class sort_timer_list {public: sort_timer_list(): head(NULL ), tail(NULL ) {} ~sort_timer_list() { util_timer *tmp = head; while (tmp) { head = tmp->next; delete tmp; tmp = head; } } void add_timer (util_timer *timer) { if (!timer) { return ; } if (!head) { head = tail = timer; return ; } if (timer->expire < head->expire) { timer->next = head; head->prev = timer; head = timer; return ; } add_timer(timer, head); } void adjust_timer (util_timer *timer) ; { if (!timer) { return ; } util_timer *tmp = timer->next; if (!tmp || (timer->expire < tmp->expire)) { return ; } if (timer == head) { head = head->next; head->prev = NULL ; timer->next = NULL ; add_timer(timer, head); } else { timer->prev->next = timer->next; timer->next->prev = timer->prev; add_timer(timer, head); } } void del_timer (util_timer *timer) { if (!timer) { return ; } if ((timer == head) && (timer == tail)) { delete timer; head = tail = NULL ; return ; } if (timer == head) { head = head->next; head->prev = NULL ; delete timer; return ; } if (timer == tail) { tail = tail->prev; tail->next = NULL ; delete timer; return ; } timer->prev->next = timer->next; timer->next->prev = timer->prev; delete timer; } void tick () { if (!head) { return ; } printf ("timer tick\n" ); time_t cur = time(NULL ); util_timer *tmp = head; while (tmp) { if (cur < tmp->expire) { breka; } tmp->cb_func(tmp->user_data); head = tmp->next; if (head) { head->prev = NULL ; } delete tmp; tmp = head; } } private: void add_timer (util_timer *timer, util_timer *lst_head) { util_timer *prev = lst_head; util_timer *tmp = prev->next; while (tmp) { if (timer->expire < tmp->expire) { prev->next = timer; timer->next = tmp; tmp ->prev = timer; timer->prev prev; break ; } prev = tmp; tmp = tmp->next; } if (!tmp) { prev->next = timer; timer->prev = prev; timer->next = NULL ; tail = timer; } } private: util_timer *head; util_timer *tail; }; #endif ;
b) 处理非活动连接
考虑上述代码的实际应用–处理非活动连接。服务器程序通常定期处理非活动连接:给客户端发送一个重连请求,或者关闭连接,或者其他。内核可以通过启动socket选项KEEPALIVE实现该功能,不过管理变的复杂,所以考虑在应用层实现类似的机制。即以下代码,利用alarm函数周期性的触发SIGALRM信号,该信号的信号处理函数利用管道通知主循环执行定时器链表上的定时任务–关闭非活动懂连接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <apra/inet.h> #include <assert.h> #include <stdio.h> #include <signal.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> #include <sys/epoll.h> #include <pthread.h> #include "timer_list.cpp" typedef int bool ;typedef struct sockaddr SA ;#define true 1 #define false 0 #define FD_LIMIT 65535 #define MAX_EVENT_NUMBER 1024 #define TIMESLOT 5 static int pipefd[2 ];static sort_timer_list timer_lst;static int epollfd = 0 ;int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd (int epollfd, int fd) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN || EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } void sig_handler (int sig) { int save_errno = errno; int msg = sig; send(pipefd[1 ], (char *)&msg, 1 , 0 ); errno = save_errno; } void addsig (int sig) { struct sigaction sa ; memset (&sa, '\0' , sizeof (sa)); sa.sa_handler = sig_handler; sa.sa_flags |= SA_RESTART; sigfillset(&sa.sa_mask); assert(sigaciton(sig, &sa, NULL ) != -1 ); } void timer_handler () { timer_lst.tick(); alarm(TIMESLOT); } void cb_func (client_data *user_data) { epoll_ctl(epollfd, EPOLL_CTL_DEL, user_data->sockfd, 0 ); assert(user_data); close(user_data->sockfd); printf ("close fd %d\n" , user_data->sockfd); } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage: error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; address.sin_port = htons(port); inet_pton(AF_INET, ip, &address.sin_addr); int listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); ret = bind(listenfd, (SA*)&address, sizeof (address)); assert(ret != -1 ); ret = listen(listenfd, 6 ); assert(ret != -1 ); struct epoll_event events [MAX_EVENT_NUMBER ]; int epollfd = epoll_create(5 ); assert(epollfd != -1 ); addfd(epollfd, listenfd); ret = socketpair(AF_UNIX, SOCK_STREAM, 0 , pipefd); assert(ret != -1 ); setnonblocking(pipefd[1 ]); addfd(epollfd, pipefd[0 ]); addsig(SIGALRM); addsig(SIGTERM); bool stop_server = false ; struct client_data *users =struct client_data*)malloc (FD_LIMIT * sizeof (sturct client_data)); bool timeout = false ; alarm(TIMESLOT); while (!stop_server) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1 ); if ((number < 0 ) && (errno != EINTR)) { printf ("epoll failure\n" ); break ; } for (int i=0 ; i<number; i++) { int sokcfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client ; socklen_t len = sizeof (client); int connfd = accept(listenfd, (SA*)&client, &len); addfd(epollfd, connfd); users[connfd].address = client; users[connfd].sockfd = connfd; struct util_timer *timer =struct util_timer*)malloc (sizeof (struct util_timer)); timer->user_data = &users[connfd]; timer->cb_func = cb_func; time_t cur = time(NULL ); timer->expire = cur + 3 *TIMESLOT; users[connfd].timer = timer; timer_lst.add_timer(timer); } else if ((sockfd == pipefd[0 ]) && (events[i].events & EPOLLIN)) { int sig; char signals[1024 ]; ret = recv(pipefd[0 ], signals, sizeof (signals), 0 ); if (ret == -1 ) { continue ; } else if (ret == 0 ) { continue ; } else { for (int i=0 ; i<ret; i++) { switch (signals[i]) { case SIGALRM: { timeout = true ; break ; } case SIGTERM: { stop_server = true ; } } } } } else if (events[i].events & EPOLLIN) { memset (users[sockfd].buf, '\0' , BUFFER_SIZE); ret = recv(sockfd, users[sockfd].buf, BUFFER_SIZE-1 , 0 ); printf ("got %d bytes of client data %s from %d\n" , ret, users[sockfd].buf, sockfd); util_timer *timer = users[sockfd].timer; if (ret < 0 ) { if (errno != EAGIN) { cb_func(&users[sockfd]); if (timer) { timer_lst.del_timer(timer); } } } else if (ret == 0 ) { cb_func(&users[sockfd]); if (timer) { timer_lst.del_timer(timer); } } else { if (timer) { time_t cur = time(NULL ); timer->expire = cur + 3 *TIMESLOT; printf ("adjust timer once\n" ); timer_lst.adjust_timer(timer); } } } } if (timeout) { timer_handler(); timeout = false ; } } close(listenfd); close(pipefd[1 ]); close(pipefd[0 ]); free (users); return 0 ; }
11.3 I/O复用系统调用的超时参数 Linux下3组I/O复用系统调用都带有超时参数。但由于I/O复用系统可能在超时时间到期之前就返回(有I/O事件发生),所以如果利用它来定时,需要不等更新定时参数剩余的时间,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #define TIMEOUT 5000 int timeout = TIMEOUT;time_t start = time(NULL );time_t end = time(NULL );while (1 ) { printf ("the timeout is now %d mil-seconds\n" , timeout); start = time(NULL ); int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, timeout); if ((number < 0 ) && (errno != EINTR)) { printf ("epoll failure\n" ); break ; } if (number == 0 ) { timeout = TIMEOUT; continue ; } end = time(NULL ); timeout -= (end-start) *1000 ; if (timeout <= 0 ) { timeout = TIMEOUT; } }
11.4 高性能定时器 a) 时间轮
哈希的思想,轮子的不同槽对应不同的超时时间,所示时间轮中,实现指针,以恒定的速度顺时针转动,每转动一步就指向下一个槽。
该图只有一个轮子,复杂的时间轮可能有多个轮子,不同的轮子拥有不同的粒度。相邻的两个轮子,精度高的转一圈,精度低的仅往前移一槽,像水表一样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 #ifdef TIME_WHEEL_TIMER #define TIME_WHEEL_TIMER #include <time.h> #include <netinet/in.h> #include <stdio.h> #define BUFFER_SIZE 64 class tw_timer ;struct client_data { sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; tw_timer *timer; }; class tw_timer {public: tw_timer(int rot, int ts) : next(NULL ), prev(NULL ), rotation(rot), time_slot(ts) {} public: int rotation; int time_slot; void (*cb_func)(client_data*); client_data *user_data; tw_timer *next; tw_timer *prev; }; class time_wheel {public: time_wheel(): cur_slot(0 ) { for (int i=0 ; i<N; i++) { slots[i] = NULL ; } } ~time_wheel() { for (int i=0 ; i<N; i++) { tw_timer *tmp = slots[i]; while (tmp) { slots[i] = tmp->next; delete tmp; tmp = slots[i]; } } } tw_timer *add_timer (int timeout) { if (timeout < 0 ) { return NULL ; } int ticks = 0 ; if (timeout < SI) { ticks = 1 ; } else { ticks = timeout/SI; } int rotation = ticks/N; int ts = (cur_slot + (ticks%N)) %N; tw_timer *timer = (tw_timer*)malloc (sizeof (tw_timer)); if (!slots[ts]) { printf ("add timer, roatation is %d, ts is %d, cur_slot is %d\n" , roatation, ts, cur_slot); slots[ts] = timer; } else { timer->next = slots[ts]; slots[ts]->prev = timer; slots[ts] = timer; } return timer; } void del_timer (tw_timer *timer) { if (!timer) { return ; } int ts = timer->time_slot; if (timer == slots[ts]) { slots[ts] = slots[ts]->next; if (slots[ts]) { slots[ts]->prev = NULL ; } free (timer); } else { timer->prev->next = timer->next; if (timer->next) { timer->next->prev = timer->prev; } free (timer); } } void tick () { tw_timer *tmp = slots[cur_slot]; printf ("current slot is %d\n" , cur_slot); while (tmp) { printf ("tick the timer once\n" ); if (tmp->rotation > 0 ) { tmp->roatation--; tmp = tmp->next; } else { tmp->cb_func(tmp->user_data); if (tmp == slots[cur_slot]) { printf ("delete header in cur_slot\n" ); slots[cur_slot] = tmp->next; free (tmp); if (slots[cur_slot]) { slots[cur_slot]->prev = NULL ; } tmp = slots[cur_slot]; } else { tmp->prev->next = tmp->next; if (tmp->next) { tmp->next->prev = tmp->prev; } tw_timer *tmp2 = tmp->next; free (tmp); tmp = tmp2; } } } cur_slot == ++cur_slot %N; } private: static const int N = 60 ; static const int SI = 1 ; tw_timer *slots[N]; int cur_slot; }; #endif ;
b) 时间堆
以最小堆为容器,每次的tick以顶端的计时器对象的timeout为tick间隔。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 #ifdef MIN_HEAP #define MIN_HEAP #include <iostream> #include <netinet/in.h> #include <time.h> using std ::exception; #define BUFFER_SIZE 64 class heap_timer ;struct client_data { sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; heap_timer *timer; }; class heap_timer {public: heap_timer(int delay) { expire = time(NULL ) + delay; } public: time_t expire; void *(cb_func)(client_data*); client_data *user_data; }; class time_heap {public: time_heap(int cap) throw(std ::exception): capacity(cap), cur_size(0 ) { array = new heap_timer*[capacity]; if (!array ) { throw std ::exception(); } for (int i=0 ; i<capacity; i++) { array [i] = NULL ; } } time_heap(heap_timer **init_array, int size, int capacity) throw(std ::exception) : cur_size(size), capacity(capacity) { if (capacity < size) { throw std ::exception; } array = new heap_timer*[capacity]; if (!array ) { throw std ::exception; } for (int i=0 ; i<capacity; i++) { array [i] = NULL ; } if (size != 0 ) { for (int i=0 ; i<size; i++) { array [i] = init_array[i]; } for (int i=(cur_size-1 )/2 ; i>=0 ; i--) { percolate_down(i); } } } ~time_heap() { for (int i=0 ; i<cur_size; i++) { delete array [i]; } delete [] array ; } public: void add_timer (heap_timer *timer) throw (std ::exception) { if (!timer) { return ; } if (cur_size >= capacity) { resize(); } int hole = cur_size++; int parent = 0 ; for (; hole>0 ; hoel=parent) { parent = (hole-1 )/2 ; if (array [parent]->expire <= timer->expire) { break ; } array [hole] = array [parent]; } array [hole] = timer; } void del_timer (heap_timer *timer) { if (!timer) { return ; } timer->cb_func = NULL ; } heap_timer *top () const { if (empty()) { return NULL ; } return array [0 ]; } void pop_timer () { if (empty()) { return ; } if (array [0 ]) { delete array [0 ]; array [0 ] = array [--cur_size]; percolate_down(0 ); } } void tick () { heap_timer *tmp = array [0 ]; time_t cur = time(NULL ); while (!empty()) { if (!tmp) { break ; } if (tmp->expire > cur) { break ; } if (array [0 ]->cb_func) { array [0 ]->cb_func(array [0 ]->user_data); } pop_timer(); tmp = array [0 ]; } } bool empty () const { return cur_size == 0 ; } private: void percolate_down (int hole) { heap_timer *temp = array [hole]; int child = 0 ; for (; ((hole*2 +1 ) <= (cur_size-1 )); hole=child) { child = hole*2 +1 ; if ((child < (cur_size-1 )) && (array [child+1 ]->expire < array [child]->expire)) { ++child; } if (array [child]->expire < temp->expire) { array [hole] = array [child]; } else { break ; } } array [hole] = temp; } void resize () throw (std ::exception) { heap_timer **temp = new heap_timer*[2 *capacity]; for (int i=0 ; i<2 *capacity; i++) { temp[i] = NULL ; } if (!temp) { throw std ::exception; } capacity = 2 *capacity; for (int i=0 ; i<cur_size; i++) { temp[i] = array [i]; } delete [] array ; array = temp; } private: heap_timer **array ; int capacity; int cur_size; }
第12章 高性能I/O框架库Libevent 12.1 I/O框架库概述 I/O框架库以库函数的形式,封装了较为底层的系统i盗用,给应用程序便于使用的接口。
各种I/O框架库的实现原理基本相似,要么基于Reactor模式,要么以Proactor模式,要么同时以两种实现。
以Reactor模式举例,基于该模式的I/O框架库包括如下几个组件:句柄,事件多路分发器,事件处理器和具体的事件处理及,Reactor。这些组件的关系,如下图。
1.句柄
I/O框架库要处理的对象,即I/O事件,信号和定时事件,统一称为事件源。一个事件源通常和一个句柄绑定在一起。在Linux中,I/O事件对应的句柄是文件描述符,信号对应的是信号值。内核检测到就绪事件,通过句柄来通知应用程序。
2.事件多路分发器
相当于epoll_wait的作用,循环等待并处理事件,也就是事件循环。通常使用I/O复用技术来实现,也就是对系统各种I/O复用函数封装成统一的接口,称为事件多路分发器。其核心函数demultiplex内部调用的是select, poll, epoll_wati等函数。
3.事件处理器和具体事件处理器
即执行事件对应的逻辑业务。通常包含一个或多个回调函数在事件循环中被执行,事件处理器为一接口,用户继承它来实现自己的事件处理器,即具体事件处理器。
4.Reactor
I/O框架库的核心。他提供如下几个主要方法:
handle_events。执行事件循环,等待事件,依次处理就绪事件对应的事件处理器。
register_handler。调用多路分发器的register_event方法注册一个事件。
remove_handler。调用多路分发器的remove_event方法删除一个事件。
12.2 Libevent源码分析 Libevent为一款轻量级的高性能I/O框架库,其特点如下:
跨平台支持,支持Linux,UNIX,Windows
统一事件源,对I/O事件,信号和定时事件提供统一的处理
线程安全。使用libevent_pthreads库来提供线程安全支持
基于Reactor模式实现。
学习它的好处:
学习编写一个产品级的函数库需要考虑的细节
a) 一个实例
Libevent库实现的一个”Hello World”程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <sys/signal.h> #include <event.h> void signal_cb (int fd, short event, void *argc) { struct event_base *base = struct timeval delay =2 , 0 }; printf ("Caught an interrupt signal; exiting cleanly in two seconds...\n" ); event_base_loopexit(base, &delay); } void timeout_cb (int fd, short event, void *argc) { printf ("timeout\n" ); } int main () { struct event_base *base = struct event *signal_event = event_add(signal_event, NULL ); timeval tv = {1 ,0 }; struct event *timeout_event =NULL ); event_add(timeout_event, &tv); event_base_dispatch(base); event_free(timeout_event); event_free(signal_event); event_base_free(base); }
由此可得出Libevent库的主要逻辑:
1.调用event_init函数创建event_base对象。相当于一个Reactor实例。
2.创建具体的事件处理器,并设置它们丛书的Reactor实例。evsignal_new和evtimer_new分别用于创建信号事件和定时器事件的处理,其定义:
1 2 3 #define evsignal_new(b, x, cb, arg) \ event_new((b), (x), EV_SIGNAL|EV_PERSIST, (cb), (arg)) #define evtimer_new(b, cb, arg) event_new((b), -1, 0, (cb), (arg))
event_new函数,用于创建通用事件处理,定义如下:
1 2 3 struct event *event_new (struct event_base *base, evutil_socket_t fd, short evetns, void (*cb)(evutil_socket_t , short , void *), void *arg)
base指定从属的Reactor,fd指定关联的句柄。I/O事件为文件描述符,信号为信号值,定时器为-1。events指定事件类型,cb指定回调函数,arg参数为传递给回调函数的参数。事件类型定义如下:
1 2 3 4 5 6 7 #define EV_TIMEOUT 0x01 #define EV_READ 0x02 #define EV_WRITE 0x04 #define EV_SIGNAL 0x08 #define EV_PERSIST 0x10 #define EV_ET 0x20
b) 源码组织结构
头文件目录include/eventw。该目录头文件是Libevent提供给应用程序使用,如event.h头文件提供核心函数,http.h头文件提供HTTP协议相关服务,rcp.h提供远程过程调用支持。
源码根目录下的头文件。分为两类:一类是对include/event2目录下部分头文件的包装,另一类是Livevent内部使用的辅助性头文件,它们的文件名具有*-internal.h的形式
通用数据结构目录compat/sys。仅有一个文件queue.h封装了跨平台的基础数据结构
sample目录。提供一些实例程序
test目录。提供一些测试代码
WIN32-Code目录。提供Windows上的一些专用代码
event.c文件,实现Libevent的整体框架
devpoll.c,kqueue.c,qvport.c,select.c,win32select.c,poll.c,epoll.c。分别封装了对应的I/O复用机制
minheap-internal.h。实现了一个时间堆
signal.c。提供对信号的支持
evmap.c。维护句柄与事件处理器的映射关系
event_tagging.c。它提供缓冲区中添加标记数据,以及从缓冲区中读出标记数据的函数
event_iocp.c。提供对WindowsIOCP的支持
buffer*.c。提供对网络I/O缓存的控制。
evthread*.c。提供多线程支持
listener.c。封装了对监听socket的操作
logs.c。Libevent的日志系统
evutil.c,evutil_rand.c,strlcpy.c和arc4random.c。提供一些基本操作:如生成随机数,获取socket地址信息,读取文件,设置socket属性等
evdns.c,http.c和evrpc.c。对DNS协议,HTTP协议和RPC协议的支持
epoll_sub.c。未使用。
c) event结构体
Libevent中的事件处理器的结构类型。封装了句柄,事件类型,回调函数以及其他必要标志。
d) 往注册事件队列中添加事件处理器
event对象创建好后,应用程序需要使用event_add函数将其添加到注册事件队列中,并将对应的事件注册到时间多路分发器上。event_add主要是调用另外一个内部函数event_add_internal。
event_add_inernal内部又调用几个重要函数:
evmap_io_add。该函数将I/O事件添加到时间多路分发器中,并将对应的事件处理器添加到I/O事件队列中,同时建立I/O事件和I/O事件处理器之间的映射关系。
evmap_signal_add。同上,但是添加到信号事件队列,以及信号和信号事件处理器之间的映射关系。
event_queue_insert。将事件处理器添加到各种事件队列中:将I/O事件处理器和信号事件处理器插入注册事件队列;定时器插入定时器队列或时间堆;被激活事件处理添加到活动时间队列。
e) 往事件多路分发器中注册事件
其中又调用add函数,注册事件。这里看起来有点复杂,还用哈希建立了文件句柄和事件处理的映射。
f) eventop结构体
封装I/O复用机制的一些操作,如注册事件,等待事件等。
g) event_base结构体
即Libevent的Reactor。
h) 事件循环
Libevent中实现事件循环的函数是event_base_loop。该函数首先调用I/O事件多路分发器的事件监听函数,以等待事件:当有事件发生时,依次处理。
第13章 多进程编程 13.1 fork系统调用 创建新进程的系统调用,定义如下:
1 2 3 #include <sys/types.h> #include <unistd.h> pid_t fork (void ) ;
大部分属性直接复制,如堆指针,栈指针和标志寄存器的值。
信号位图被清除,PPID被设置成原进程的PID。
写时复制。
父进程打开的文件描述符默认在子进程中也是打开的。
13.2 exec系列系统调用 在子进程中执行其他程序,即替换当前进程映像:
1 2 3 4 5 6 7 8 9 #include <unistd.h> extern char **environ;int execl (const char *path, const char *arg, ...) ;int execlp (const char *file, const char *arg, ...) ;int execle (const char *path, const char *arg, ..., char *const envp[]) ;int execv (const char *file, char *const argv[]) ;int execvp (const char *file, char *const argv[]) ;int execve (const char *path, char *const argv[], char *const envp[]) ;
exec函数不会关闭原程序打开的文件描述符,除非该文件描述符被设置了类似SOCK_CLOEXEC的属性。
13.3 处理僵尸进程 父进程调用如下函数,以等待子进程的结束,并获取子进程的返回信息,避免僵尸进程的产生:
1 2 3 4 #include <sys/types.h> #include <sys/wait.h> pid_t wait (int *stat_loc) ;pid_t waitpid (pid_t pid, int *stat_loc, int options) ;
退出状态信息储存于stat_loc参数,wait.h中定义了几个宏来帮助解释子进程的退出状态信息:
宏
含义
WIFEXITED(stat_val)
如果子进程正常结束,它就返回一个非0值
WEXITSTATUS(stat_val)
如果WIFEXITED非0,它返回子进程的退出码
WIFSIGNALED(stat_val)
如果子进程是因为一个未捕捉的信号而终止,它就返回一个非0值
WTERMSIG(stat_val)
如果WIFSIGNALED非0,它返回一个信号值
WIFSTOPPED(stat_val)
如果子进程意外终止,它就返回一个非0值
WSTOPSIG(stat_val)
如果WIFSTOPPED非0,它返回一个信号值
wait函数带有阻塞,取而代之的是waitpid。如果pid为-1,它和wait函数相同,等待一个任意的子进程结束,否则等待由pid参数指定的子进程。
options参数可以控制其行为,常用的取值为WNOHANG,即调用为非阻塞。
8.3提过,要在事情已经发生的情况下执行非阻塞调用才能提高效率,所以可以利用SIGCHLD信号,得知某个进程是否已经退出,然后对其处理函数进行处理。
1 2 3 4 5 6 7 8 9 static void handle_child (int sig) { pid_t pid; int stat; while ((pid = waitpid(-1 , &stat, WNOHANG)) > 0 ) { } }
13.4 管道 管道也是父子进程之间通信的常用手段。利用的是fork调用之后两个管道文件描述符都保持打开。
普通的管道只能实现单向数据传输,如果要实现父子之间的双向数据传输,必须使用两个管道。或前面介绍过的,socketpari函数,创建全双工管道的系统调用。
管道只能用于有关联的两个进程间的通信,下面讨论3种System V IPC能用于无关联的多个进程之间的通信,因为它们都使用一个全局唯一的键值来标识一条信道。
13.5 信号量 a) 信号量原语
用起来感觉和锁差不多的,多进程中,某进程访问一资源的时候,避免其他线程也同时访问,也就是独占式访问。
信号量的操作主要为如下两种,假设信号量SV:
P(SV):如果SV的值大于0,将它减1;如果SV的值为0,挂起进程的执行。
V(SV):如果有其他进程因为等待SV而挂起,则唤醒之;如果没有,将SV加1。
如图,在关键代码可用时,假设信号量SV的值为1。AB都有机会进入该段,如果A执行了PSV,将SV值减1,则进程B再次执行PSV则会被挂起。直到A执行VSV操作将SV加1,关键代码段才重新可用。
b) semget系统调用
创建一个新的信号量集,或者获取一个已存在的信号量集。
1 2 #include <sys/sem.h> int semget (key_t key, int num_sems, int sem_flags) ;
key参数是一个键值,标识一个全局唯一的信号量集。
num_sems参数指定要创建/获取的信号量集中信号量的数目。
sem_flags参数指定一组标志,权限。和open系统调用的mode参数一样,即0777这种格式的权限。
如果semget用于创建信号量集,则与之关联的内核数据结构体semid_ds将被创建,结构定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <sys/sem.h> struct ipc_perm { key_t key; uid_t uid; gid_t gid; uid_t cuid; gid_t cgid; mode_t mode; }; struct semid_ds { struct ipc_perm sem_perm ; unsigned long int sem_nsems; time_t sem_otime; time_t sem_ctime; };
c) semop系统调用
semop改变信号量的值,即执行P,V操作。
每个信号量关联的一些重要的内核变量:
1 2 3 4 unsigned short semval; unsigned short semzcnt; unsigned short semncnt; pid_t sempid;
semop定义如下:
1 2 #include <sys/sem.h> int semop (int sem_id, struct sembuf *sem_ops, size_t num_sem_ops) ;
sem_id参数即semget获取/创建的信号量集标识符。
sem_ops参数指向一个sembuf的结构体,定义如下:
1 2 3 4 5 struct sembuf { unsigned short int sem_num; short int sem_op; short int sem_flg; };
sem_num成员指明信号量集中信号量的编号,0表示第一个。
sem_op指定操作类型,可选值为正整数,0,负整数。其操作的行为又受到sem_flg影响。
sem_flg的可选值为IPC_NOWAIT和SEM_UNDO。IPC_NOWAIT类似于非阻塞操作。SEM_UNDO的含义是进程退出时取消正在进行的semop操作。
sem_flg影响如下:
如sem_op大于0,对信号量的值semval增加sem_op,类似V操作。要求调用进程对信号量具有写权限,如果设置了UNDO标志,则系统将更新semadj变量(用以跟踪进程对信号量的修改情况)。
如sem_op等于0,表示这是一个“等待0”操作。要求拥有读权限。如没设置IPC_NOWAIT,信号量的semzcnt值加1,进程睡眠直到以下三个情况发生:a) semval变为0;b) 信号量集被进程移除;c) 调用被信号中断。
如sem_op小于0,灯信号量进行减操作,类似P操作,即期望获得信号量。如设置UNDO标志,系统更新semadj变量。
semop的第3个参数num_sem_ops指定要执行的操作个树,即sem_ops数组元素的数量,对数组每个成员按顺序依次执行操作,且该过程为 原子操作。
d) semctl系统调用
该系统调用允许调用者对信号量进行直接控制:
1 2 #include <sys/sem.h> int semctl (int sem_id, int sem_num, int command, ...) ;
id参数指定信号量集的标识符,sem_num指定被操作的信号量在集中的编号,command指定要执行的命令。
有的命令需要第4个参数,第4个参数类型由用户自己定义,推荐格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 union semun { int val; struct semid_ds *buf , //用于IPC_STAT 和IPC_SET 命令 unsigned short *array ; struct seminfo *__buf ; }; struct seminfo { int semmap; int semmni; int semmns; int semmnu; int semmsl; int semopm; int semume; int semusz; int semvmx; int semaem; }
所有支持的命令如下表:
e) 特殊键值IPC_RPIVATE
并非像它的名字是私有的,而是创建一个新的信号量,类似INADDR_ANY。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <sys/sem.h> #include <stdio.h> #include <stdlib.h> #include <sys/wait.h> union semun { int val; struct semid_ds *buf ; unsigned short int *array ; struct seminfo *__buf ; }; void pv (int sem_id, int op) { struct sembuf sem_b ; sem_b.sem_num = 0 ; sem_b.sem_op = op; sem_b.sem_flg = SEM_UNDO; semop(sem_id, &sem_b, 1 ); } int main (int argc, char *argv[]) { int sem_id = semget(IPC_PRIVATE, 1 , 0666 ); union semun sem_un ; sem_un.val = 1 ; semctl(sem_id, 0 , SETVAL, sem_un); pid_t id = fork(); if (id < 0 ) { return 1 ; } else if (id == 0 ) { printf ("child try to get binary sem\n" ); pv(sem_id, -1 ); printf ("child get the sem and would release it after 5s\n" ); sleep(5 ); pv(sem_id, 1 ); exit (0 ); } else { printf ("parent try to get binary sem\n" ); pv(sem_id, -1 ); printf ("parent get the sem and would release it after 5s\n" ); sleep(5 ); pv(sem_id, 1 ); } waitpid(id, NULL , 0 ); semctl(sem_id, 0 , IPC_RMID, sem_un); return 0 ; }
可以看出信号量和互斥锁还是很像的,区别在于信号量的lock操作也就是p操作不一定会导致其他线程被挂起。
13.6 共享内存 共享内存通常和其他进程间通信方式一起使用,以防止产生竞态条件,其包括4个系统调用:shmget,shmat,shmdt和shmctl。
a) shmget系统调用
创建一段新的共享内存,或者获取一段已存在的共享内存:
1 2 #include <sys/shm.h> int shmget (key_t key, size_t size, int shmflg) ;
key同semget一样,标识符。size指定共享内存的大小。
shmflg同semget一样,类似于open系统调用的mode参数,但支持两个额外参数:
SHM_HUGETLB。类似于mmap的MAP_HUGETLB标志,使用“大页面”来分配空间。
SHM_NORESERVE。类似于mmap的MAP_NORESERVE标志,不保留交换分区。这样,当物理内存不足时,将触发SIGSEGV信号。
同样,也存在一个与之关联的内核数据结构shmid_ds,定义如下:
1 2 3 4 5 6 7 8 9 10 struct shmid_ds { struct ipc_perm shm_perm ; size_t shm_segsz; __time_t shm_atime; __time_t shm_dtime; __time_t shm_ctime; __pid_t shm_cpid; __pid_t shm_lpid; shmatt_t shm_nattach; }
b) shmat和shmdt系统调用
共享内存被创建/获取之后,需要将它关联到进程的地址空间中,使用完后也需要将他分离。
1 2 3 #include <sys/shm.h> void *shmat (int shm_id, const void *shm_addr, int shmflg) ;int shmdt (const void *shm_addr) ;
如shm_addr为NULL,被关联地址由操作系统选择。
如shm_addr非空,SHM_RND标志未设置,则关联到addr指定的地址处
如shm_addr非空,SHM_RND标志已设置,则被关联的地址[shm_addr - (shm_addr % SHMLBA)]。
shmflg除SHM_RND参数之外,还支持如下:
SHM_RDONLY,仅能读取。
SHM_REMAP,重新关联。
SHM_EXEC,指定执行权限。
c) shmctl系统调用
控制共享内存的某些属性,定义如下:
1 2 #include <sys/shm.h> int shmctl (int shm_id, int command, struct shmid_ds *buf) ;
支持的命令如下表:
d) 共享内存POSIX方法
即mmap函数。利用它的MAP_ANONYMOUS标志,可以实现父子进程之间的匿名共享内存。通过打开同一个文件,mmap也可以实现无关进程之间的内存共享。Linux提供了另外一种利用mmap在无关进程之间共享内存的方法,定义如下:
1 2 3 4 #include <sys/mman.h> #include <sys/stat.h> #include <fcntl.h> int shm_open (const char *name, int oflag, mode_t mode) ;
由shm_open创建的共享内存对象,使用完之后需要被删除:
1 2 3 4 #include <sys/mman.h> #include <sys/stat.h> #include <fcntl.h> int shm_unlink (const char *name) ;
e) 共享内存实例
一个聊天室服务器程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <stdio.h> #include <unistd.h> #include <errno.h> #include <string.h> #include <fcntl.h> #include <stdlib.h> #include <sys/epoll.h> #include <signal.h> #include <sys/wait.h> #include <sys/mman.h> #include <sys/stat.h> #include <fcntl.h> typedef int bool ;#define true 1 #define false 0 #define USER_LIMIT 5 #define BUFFER_SIZE 1024 #define FD_LIMIT 65535 #define MAX_EVENT_NUMBER 1024 #define PROCESS_LIMIT 65536 struct client_data { sockaddr_in address; int connfd; pid_t pid; int pipefd[2 ]; }; static const char *shm_name = "/my_shm" ;int sig_pipefd[2 ];int epollfd;int listenfd;int shmfd;char *share_mem = 0 ;struct client_data *users =0 ;int *sub_process = 0 ;int user_count = 0 ;bool stop_child = false ;int setnonblocking (int fd) { int old_option = fcntl(fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl(fd, F_SETFL, new_option); return old_option; } void addfd (int epollfd, int fd) { struct epoll_event event ; event.data.fd = fd; event.events = EPOLLIN | EPOLLET; epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking(fd); } void sig_handler (int sig) { int save_errno = errno; int msg = sig; send(sig_pipefd[1 ], (char *)*msg, 1 , 0 ); errno = save_errno; } void addsig (int sig, void *(handler)(int ), bool restart = true ) { struct sigaction as ; memset (&sa, '\0' , sizeof (sa)); sa.sa_handler = handler; if (restart) { sa.sa_flags |= SA_RESTART; } sigfillset(&sa.sa_mask); assert(sigaction(sig, &sa, NULL ) != -1 ); } void del_resource () { close(sig_pipefd[0 ]); close(sig_pipefd[1 ]); close(listenfd); close(epollfd); shm_unlink(shm_name); delete [] users; delete [] sub_process; } void child_term_handler (int sig) { stop_child = true ; } int run_child (int idx, client_data *users, char *share_mem) { struct epoll_event events [MAX_EVENT_NUMBER ]; int child_epollfd = epoll_create(5 ); assert(child_epollfd != -1 ); int connfd = users[idx].connfd; addfd(child_epollfd, connfd); int pipefd = users[idx].pipefd[1 ]; addfd(child_epollfd, pipefd); int ret; addsig(SIGTERM, child_term_handler, false ); while (!stop_child) { int number = epoll_wait(child_epollfd, events, MAX_EVENT_NUMBER, -1 ); if ((number < 0 ) && (errno != EINTR)) { printf ("epoll failure\n" ); break ; } for (int i=0 ; i<number; i++) { int sockfd = events[i].data.fd; if ((sockfd == connfd) && (events[i].events & EPOLLIN)) { memset (share_mem+idx*BUFFER_SIZE, '\0' , BUFFER_SIZE); ret = recv(connfd, share_mem+idx*BUFFER_SIZE, BUFFER_SIZE-1 , 0 ); if (ret < 0 ) { if (errno != EINTR) stop_child = true ; } else if (ret == 0 ) { stop_child = true ; } else { send(pipefd, (char *)&idx, sizeof (idx), 0 ); } } else if ((sockfd == pipefd) && (events[i].events & EPOLLIN)) { int client = 0 ; ret = recv(sockfd, (char *)&client, sizeof (client), 0 ); if (ret < 0 ) { if (errno != EAGAIN) stop_child = true ; } else if (ret == 0 ) { stop_child = true ; } else { send(connfd, share_mem+client*BUFFER_SIZE, BUFFER_SIZE, 0 ); } } else { continue ; } } } close(connfd); close(pipefd); close(child_epollfd); return 0 ; } int main (int argc, char *argv[]) { if (argc <= 2 ) { printf ("usage:error\n" ); return 1 ; } const char *ip = argv[1 ]; int port = atoi(argv[2 ]); int ret = 0 ; struct sockaddr_in address ; bzero(&address, sizeof (address)); address.sin_family = AF_INET; inet_pton(AF_INET, ip, &address.sin_addr); address.sin_port = port; listenfd = socket(AF_INET, SOCK_STREAM, 0 ); assert(listenfd >= 0 ); ret = bind(listenfd, (struct sockaddr*)&address, sizeof (address)); assert(ret != -1 ); ret = listen(listenfd, 5 ); assert(ret != -1 ); user_count = 0 ; users = new clinet_data[USER_LIMIT+1 ]; sub_process = new int [PROCESS_LIMIT]; for (int i=0 ; i<PROCESS_LIMIT; i++) sub_process[i] = -1 ; struct epoll_event events [MAX_EVENT_NUMBER ]; epollfd = epoll_create(5 ); assert(epollfd != -1 ); addfd(epollfd, listenfd); ret = socketpair(AF_UNIX, SOCK_STREAM, 0 , sig_pipefd); assert(ret != -1 ); setnonblocking(sig_pipefd[1 ]); addfd(epollfd, sig_pipefd[0 ]); addsig(SIGCHLD, sig_handler); addsig(SIGTERM, sig_handler); addsig(SIGINT, sig_handler); addsig(SIGPIPE, SIG_IGN); bool stop_server = false ; bool terminate = false ; shmfd = shm_open(shm_name, O_CREAT | P_RDWR, 0666 ); assert(shmfd != -1 ); ret = ftruncate(shmfd, USER_LIMIT * BUFFER_SIZE); assert(ret != -1 ); share_mem = (char *)mmap(NULL , USER_LIMIT*BUFFER_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, shmfd, 0 ); assert(share_mem != MAP_FAILED); close(shmfd); while (!stop_server) { int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1 ); if ((number < 0 ) && (errno != EINTR)) { printf ("epoll failure\n" ); break ; } for (int i=0 ; i<number; i++) { int sockfd = events[i].data.fd; if (sockfd == listenfd) { struct sockaddr_in client_address ; socklen_t clientlen = sizeof (client_address); int connfd = accept(listenfd, (struct sockaddr*)&client_address, &clientlen,); if (connfd < 0 ) { printf ("errno is :%d\n" ); continue ; } if (user_count >= USER_LIMIT) { const char *info = "too many users\n" ; printf ("%s" , info); send(connfd, info, strlen (info), 0 ); close(connfd); continue ; } users[user_count].address = client_address; users[user_count].connfd = connfd; ret = socketpair(AF_UNIX, SOCK_STREAM, 0 , users[user_count].pipefd); assert(ret != -1 ); pid_t pid = fork(); if (pid<0 ) { close(connfd); continue ; } else if (pid == 0 ) { close(epollfd); close(listenfd); close(users[user_count].pipefd[0 ]); close(sig_pipefd[0 ]); close(sig_pipefd[1 ]); run_child(user_count, users, share_mem); munmap((void *)share_mem, USER_LIMIT*BUFFER_SIZE); exit (0 ); } else { close(connfd); close(users[user_count].pipefd[1 ]); addfd(epollfd, user[user_count].pipefd[0 ]); users[user_count].pid = pid; sub_process[pid] = user_count; user_count++; } } else if (sockfd == sig_pipefd[0 ] && (events[i].events & EPOLLIN)) { int sig; char signals[1024 ]; ret = recv(sig_pipefd[0 ], signals, sizeof (signals), 0 ); if (ret == -1 ) { continue ; } else if (ret == 0 ) { continue ; } else { for (int i=0 ; i<ret; i++) { switch (signals[i]) { case SIGCHLD: { pid_t pid; int stat; while ((pid = waitpid(-1 , &stat, WNOHANG)) > 0 ) { int del_user = sub_process[pid]; sub_process[pid] = -1 ; if ((del_user < 0 ) || (del_user > USER_LIMIT)) continue ; epoll_ctl(epollfd, EPOLL_CTL_DEL, users[del.user].pipefd[0 ]); close(user[del_user].pipefd[0 ]); users[del_user] = users[--user_count]; sub_process[user[del_user].pid] = del_user; } if (terminate && user_count == 0 ) stop_server = true ; break ; } case SIGTERM: case SIGINT: { printf ("kill all the child now\n" ); if (user_count == 0 ) { stop_server = true ; break ; } for (int i=0 ; i<user_count; i++) { int pid = users[i].pid; kill(pid, SIGTERM); } terminate = true ; break ; } default : { break ; } } } } } else if (events[i].events & EPOLLIN) { int child = 0 ; ret = recv(sockfd, (char *)&child, sizeof (child), 0 ); printf ("read data from child accross pipe\n" ); if (ret == -1 ) { continue ; } else if (ret == 0 ) { continue ; } else { for (int j=0 ; j<user_count; j++) { if (users[j].pipefd[0 ] != sockfd) { printf ("send data to child accross pipe\n" ); send(users[j].pipefd[0 ], (char *)&child, sizeof (child), 0 ); } } } } } } del_resource(); return 0 ; }
13.7 消息队列 消息队列是两个进程之间传递二进制块数据的一种简单有效的方式。每个数据块都有一个特定的类型,接受方可以根据类型来有选择地接收数据。
包括4个系统调用:msgget,msgsnd,msgrcv和msgctl。
a) msgget系统调用
创建/获取一个消息队列:
1 2 #include <sys/msg.h> int msgget (key_t key, int msgflg) ;
key键值标识一个全局唯一的消息队列。msfflg类似于open的mode参数。
与之关联的内核数据结构msqid_ds定义如下:
1 2 3 4 5 6 7 8 9 10 11 struct msqid_ds { struct ipc_perm msg_perm ; time_t msg_stime; time_t msg_rtime; time_t msg_ctime; unsigned long __msg_cbytes; msgqnum_t msg_qnum; msgqlen_t msg_qbytes; pid_t msg_lspid; pid_t msg_lrpid; };
b) msgsnd系统调用
将一条消息添加到消息队列中:
1 2 #include <sys/msg.h> int msgsnd (int msqid, const void *msg_ptr, size_t msg_sz, int msgflg) ;
msqid指定一个消息队列标识符。
msg_ptr指向一个准备发送的消息,消息必须被定义为如下类型:
1 2 3 4 struct msgbuf { long mtype; char mtext[512 ]; };
mtype指定消息的类型,必须为一个正整数。
msgflg控制msgsnd的行为,通常仅支持IPC_NOWAIT。
c) msgrcv系统调用
从消息队列中获取消息,定义如下:
1 2 #include <sys/msg.h> int msgrcv (int msqid, void *msg_ptr, size_t msg_sz, long int msgtype, int msgflg) ;
msgtype参数指定接收何种类型的消息,可使用如下几种方式:
等于0,读取队列中第一个消息。
大于0,读取队列中第一个类型为msgtype的消息(除非指定了MSG_EXCEPT)。
小于0,读取队列中第一个类型比msgtype的绝对值小的消息。
msgflg参数控制msgrcv的行为,如下:
IPC_NOWWAIT,非阻塞读。
MSG_EXCEPT,如果msgtype大于0,则接收队列中第一个非msgtype类型的消息。
MSG_NOERROR,如果长度超过了msg_sz,将它截断。
d) msgctl系统调用
控制消息队列的某些属性:
1 2 #include <sys/msg.h> int msgctl (int msqid, int command, struct msqid_ds *buf) ;
支持的命令如下表:
13.8 IPC命令 ipcs命令,查看当前系统上拥有哪些共享资源实例,如下:
13.9 在进程间传递文件描述符 在Linux下,可以利用UNIX域socket在进程间传递特殊的辅助数据,以实现文件描述符的传递。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 #include <sys/socket.h> #include <fcntl.h> #include <stdio.h> #include <unistd.h> #include <stdlib.h> #include <assert.h> #include <string.h> static const int CONTROL_LEN = CMSG_LEN(sizeof (int ));void send_fd (int fd, int fd_to_send) { struct iovec iov [1]; struct msghdr msg ; char buf[0 ]; iov[0 ].iov_base = buf; iov[0 ].iov_len = 1 ; msg.msg_name = NULL ; msg.msg_namelen = 0 ; msg.msg_iov = iov; msg.msg_iovlen = 1 ; struct cmsghdr cm ; cm.cmsg_len = CONTROL_LEN; cm.cmsg_level = SOL_SOCKET; cm.cmsg_type = SCM_RIGHTS; *(int *)CMSG_DATA(&cm) = fd_to_send; msg.msg_control = &cm; msg.msg_controllen = CONTROL_LEN; sendmsg(fd, &msg, 0 ); } int recv_fd (int fd) { struct iovec iov [1]; struct msghdr msg ; char buf[0 ]; iov[0 ].iov_base = buf; iov[0 ].iov_len = 1 ; msg.msg_name = NULL ; msg.msg_namelen = 0 ; msg.msg_iov = iov; msg.msg_iovlen = 1 ; struct cmsghdr = msg.msg_control = &cm; msg.msg_controllen = CONTROL_LEN; recvmsg(fd, &msg, 0 ); int fd_to_read = *(int *)CMSG_DATA(&cm); return fd_to_read; } int main () { int pipefd[2 ]; int fd_to_pass = 0 ; int ret = socketpair(AF_UNIX, SOCK_DGRAM, 0 , pipefd); assert(ret != -1 ); pid_t pid = fork(); assert(pid >= 0 ); if (pid == 0 ) { close(pipefd[0 ]); fd_to_pass = open("test.txt" , O_RDWR, 0666 ); send_fd(pipefd[1 ], (fd_to_pass > 0 ) ? fd_to_pass : 0 ); close(fd_to_pass); exit (0 ); } close(pipefd[1 ]); fd_to_pass = recv_fd(pipefd[0 ]); char buf[1024 ]; memset (buf, '\0' , 1024 ); read(fd_to_pass, buf, 1024 ); printf ("I got fd %d and data %s\n" , fd_to_pass, buf); close(fd_to_pass); }
第14章 多线程编程
创建线程和结束线程
读取和设置线程属性
POSIX线程同步方式:POSIX信号量,互斥锁和条件变量
14.1 Linux线程概述 a) 线程模型
线程分为内核线程和用户线程。它们的关系相当于,内核线程是用户线程的”容器”,当进程的一个内核线程获得CPU的使用权时,它就加载并允许一个用户线程。一个进程可以拥有M个内核线程和N个用户线程,M<=N。按照M:N的取值分为三种模式:完全在用户空间实现,完全由内核调度,双层调度。
b) Linux线程库
Linux上两个有名的线程库LinuxThreads和NPTL。现代Linux默认使用的是NPTL。用如下命令查看:
1 $ getconf GNU_LIBPTHREAD_VERSION
LinuxThreads的内核线程是用clone系统调用创建的进程模拟的。因为是模拟的,所以导致了很多语义问题。另一个特性是,其引入了所谓的管理线程,专门用于管理其他工作线程的线程。管理线程的引入,增加了额外的系统开销,并且由于它只能运行在一个CPU上,所以LinuxThreads线程库也不能充分利用多处理器系统的优势。
因此Linux内核从2.6版本开始,提供真正的内核线程。新的NPTL线程库应运而生,其优势:
内核线程不再是一个进程,避免了很多进程模拟线程的语义问题。
摒弃了管理线程,终止线程丶回收线程堆栈工作由内核完成。
由于不存在管理线程,同一个进程的线程可以运行在不同CPU上。
线程的同步由内核来完成,隶属于不同进程的线程之间也能共享互斥锁。
14.2 创建线程和结束线程 a) pthread_create
创建一个线程的函数:
1 2 3 #include <pthread.h> int pthread_create (pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg) ;
thread参数即线程ID,其类型定义如下:
1 2 #include <bits/pthreadtype.h> typedef unsigned long int pthread_t ;
attr参数设置线程的属性,NULL标识默认,后面讨论。
start_routine和arg分别指定线程函数和其参数。
b) pthread_exit
线程函数结束时最好调用如下函数,以确保安全,干净地退出:
1 2 #include <pthread.h> void pthread_exit (void *retval) ;
retval参数向线程的回收者传递其退出信息。该函数永远不会失败。
c) pthread_join
回收线程,类似于wait和waitpid系统调用:
1 2 #include <pthread.h> int pthread_join (pthread_t thread, void **retval) ;
retval是目标线程退出返回的退出信息。
可能引发的错误码表如下:
d) pthread_cancel
异常终止一个线程,即取消线程:
1 2 #include <pthread.h> int pthread_cancel (pthread_t thread) ;
接收到取消请求的目标线程可以决定似乎否被取消以及如何取消,通过如下两个函数完成:
1 2 3 #include <pthread.h> int pthread_setcancelstate (int state, int *oldstate) ;int pthread_setcanceltype (int type, int *oldtype) ;
state的可选值如下:
PTHREAD_CANCEL_ENABLE,允许线程被取消。默认状态。
PTHREAD_CANCEL_DISABLE,将取消请求挂起,直到线程允许取消。
type的可选值如下:
PTHREAD_CANCEL_ASYNCHROUNOUS,线程随时可以被取消。
PTHREAD_CANCEL_DEFERRED,允许目标线程推迟行动,直到它调用了所谓的取消点函数。
取消点函数如:pthread_join,pthread_testcancel,pthread_cond_wati,pthread_cond_timewati,sem_wati和sigwait。
14.3 线程属性 pthread_attr_t结构体定义了一套完整的线程属性,如下:
1 2 3 4 5 6 #include <bits/pthreadtypes.h> #define __SIZEOF_PTHREAD_ATTR_T 36 typedef union { char __size[__SIZEOF_PTHREAD_ATTR_T]; long int __align; }pthread_attr_t ;
线程库定义了一系列函数来操作pthread_attr_t类型的变量,以设置/获取线程属性。
含义如下:
detachstate,设置线程分离,即手动调用pthread_join回收,还是线程自行释放。
stackaddr和stacksize,手动设置线程堆栈的起始地址和大小。
guardsize,保护区域大小。
schedparam,线程调度参数,表示线程的运行优先级。
schedpolicy,线程调度策略,三个可选值:SCHED_FIFO,SCHED_RR和SCHED_OTHREAD,other默认值,rr表示轮转算法,fifo表示先进先出调度。
inheritsched,是否继承调用线程的调度属性。
scope,线程间竞争CPU的范围,即线程优先级的有效范围,Linux仅支持PTHREAD_SCOPE_SYSTEM,即表示与系统中所有线程竞争CPU。
14.4 POSIX信号量 如下5个:
1 2 3 4 5 6 #include <semaphore.h> int sem_init (sem_t *sem, int pshared, unsigned int value) ;int sem_destroy (sem_t *sem) ;int sem_wait (sem_t *sem) ;int sem_trywait (sem_t *sem) ;int sem_post (sem_t *sem) ;
seminit用于初始化一个未命名的信号量;pshared指定信号量的类型,如果为0,表示是当前进程的局部信号量,否则可以在多个进程之间共享;value指定初始值。
sem_destroy用于销毁信号量。
sem_wati和sem_trywait对信号量执行减1操作,即p操作。
post将值加1,如果值大于0,唤醒其他等待信号量的线程,即v操作。
14.5 互斥锁 类似于一个二进制信号量,lock相当于p操作,unlock相当于v操作
a) 互斥锁基础API
如下5个:
1 2 3 4 5 6 #include <pthread.h> int pthread_mutex_init (pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr) ;int pthread_mutex_destroy (pthread_mutex_t *mutex) ;int pthread_mutex_lock (pthread_mutex_t *mutex) ;int pthread_mutex_unlock (pthread_mutex_t *mutex) ;int pthread_mutex_trylock (pthread_mutex_t *mutex) ;
mutex指定要操作的目标互斥锁,类型是pthread_mutex_t 结构体。
init初始化互斥锁,mutexattr指定互斥锁属性,后面讨论,NULL表示默认。还可以用如下方式初始化互斥锁:
1 pthread_mutex_t mutex = PTHREAD_MUTEX_INITALIZER;
destroy销毁互斥锁。
lock加锁,即p操作。
unlock解锁,即v操作。
b) 互斥锁属性
线程库提供了如下函数,来操作pthread_mutexattr_t 类型的变量,如下:
1 2 3 4 5 6 7 8 9 10 11 #include <pthread.h> int pthread_mutexattr_init (pthread_mutexattr_t *attr) ;int pthread_mutexattr_destroy (pthread_mutexattr_t *attr) ;int pthread_mutexattr_getshared (const pthread_mutexattr_t *attr, int *pshared) ;int pthread_mutexattr_setpshared (pthread_mutexattr_t *attr, int pshared) ;int pthread_mutexattr_gettype (const pthread_mutexattr_t *attr, int *type) ;int pthread_mutexattr_settype (pthread_mutexattr_t *attr, int type) ;
本书只讨论两种常用属性:pshared和type。
pshared指定是否允许跨进程共享互斥锁,可选值如下:
PTHREAD_PROCESS_SHARED,可以被跨进程。
PTHREAD_PROCESS_PRIVATE,不行。
type指定互斥锁的类型,如下:
PTHREAD_MUTEX_NORMAL,普通锁。问题可能导致死锁。
PTHREAD_MUTEX_ERRORCHECK,检错锁。多次对同一个锁加锁,返回EDEADLK,对一个以及被其他线程加锁的检错所解锁,或者对一个解锁的锁再次解锁,返回EPERM。
PTHREAD_MUTEX_RECURSIVE,嵌套所。允许多次加锁而不死锁,但解锁也需要执行对应次数的解锁操作。对一个其他线程加锁的嵌套锁解锁,或对以解锁的解锁,返回EPERM。
PTHREAD_MUTEX_DEFAULT,默认锁。
c) 死锁举例
死锁会导致一个或多个线程被挂起无法继续执行,即一个线程中多次加锁会导致死锁,可能发生于设计不够仔细的递归函数。以及,两个线程按照不同的顺序来申请两个互斥锁,也容易产生死锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <pthread.h> #include <unistd.h> #include <stdio.h> int a = 0 ;int b = 0 ;pthread_mutex_t mutex_a;pthread_mutex_t mutex_b;void *another (void *arg) { pthread_mutex_lock(&mutex_b); printf ("in child thread, got mutex b, waiting for mutex a\n" ); sleep(5 ); ++b; pthread_mutex_lock(&mutex_a); b+=a++; pthread_mutex_unlock(&mutex_a); pthread_mutex_unlock(&mutex_b); pthread_exit(NULL ); } int main () { pthread_t tid; pthread_mutex_init(&mutex_a, NULL ); pthread_mutex_init(&mutex_b, NULL ); pthread_create(&tid, NULL , another, NULL ); pthread_mutex_lock(&mutex_a); printf ("in parent thread, got mutex a, waiting for mutex b\n" ); sleep(5 ); ++a; pthread_mutex_lock(&mutex_b); a+=b++; pthread_mutex_unlock(&mutex_b); pthread_mutex_unlock(&mutex_a); pthread_join(tid, NULL ); pthread_mutex_destroy(&mutex_a); pthread_mutex_destroy(&mutex_b); return 0 ; }
14.6 条件变量 条件变量提供了一种线程间的通知机制:当某个共享数据达到某个值的时候,唤醒等待这个共享数据的线程。
相关函数如下:
1 2 3 4 5 6 #include <pthread.h> int pthread_cond_init (pthread_cond_t *cond, const pthread_condattr_t *cond_attr) ;int pthread_cond_destroy (pthread_cond_t cond) ;int pthread_cond_broadcast (pthread_cond_t *cond) ;int pthread_signal (pthread_cond_t *cond) ;int pthread_cond_wait (pthread_cond_t *cond, pthread_mutex_t *mutex) ;
init函数用来初始化,还可以使用如下方式:
1 pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
14.7 线程同步机制包装类 将3个线程同步机制分别封装成3个类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 #ifndef LOCKER_H #define LOCKER_H #include <exception> #include <pthread.h> #include <semaphore.h> class sem {public: sem() { if (sem_init(&m_sem, 0 , 0 ) != 0 ) { throw std ::exception(); } } ~sem() { sem_destroy(&m_sem); } bool wait () { return sem_wait(&m_sem) == 0 ; } bool post () { return sem_post(&m_sem) == 0 ; } private: sem_t m_sem; }; class locker {public: locker() { if (pthread_mutex_init(&m_mutex, NULL ) != 0 ) { throw std ::exception(); } } ~locker() { pthread_mutex_destroy(&m_mutex); } bool lock () { return pthread_mutex_lock(&m_mutex) == 0 ; } bool unlock () { return pthread_mutex_unlock(&m_mutex) == 0 ; } private: pthread_mutex_t m_mutex; }; class cond {public: cond() { if (pthread_mutex_init(&m_mutex, NULL ) != 0 ) { throw std ::exception(); } if (pthread_cond_init(&m_cond, NULL ) != 0 ) { pthread_mutex_destroy(&m_mutex); throw std ::exception(); } } ~cond() { pthread_mutex_destroy(&m_mutex); pthread_cond_destroy(&m_cond); } bool wait () { int ret = 0 ; pthread_mutex_lock(&m_mutex); ret = pthread_cond_wait(&m_cond, m_mutex); pthread_mutex_unlock(&m_mutex); return ret == 0 ; } bool signal () { return pthread_cond_signal(&m_cond) == 0 ; } private: pthread_mutex_t m_mutex; pthread_cond_t m_cond; }; #endif ;
14.8 多线程环境 a) 可重入函数
如果一个函数能够被多个线程同时调用且不发生竞态条件,则称之为线程安全的,或者说可重入函数。Linux对很多不可重入的库函数提供了对应的可重入版本,这些可重入版本是在原函数名尾部加上_r。在多线程程序中调用库函数,一定要使用其可重入版本。
b) 线程和进程
一个多线程程序的某个线程调用fork函数,先创建的子进程不会自动创建和父进程相同数量的线程。但他会自动鸡翅父进程中互斥锁的状态,由此可能导致,自己才能不清楚锁的具体状态,从而再次加锁导致死锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <pthread.h> #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <wait.h> pthread_mutex_t mutex;void *another (void *arg) { pthread_mutex_lock(&mutex); sleep(5 ); pthread_mutex_unlock(&mutex); } int main () { pthread_mutex_init(&mutex, NULL ); pthread_t id; pthread_create(&id, NULL , another, NULL ); sleep(1 ); int pid = fork(); if (pid < 0 ) { pthread_join(id, NULL ); pthread_mutex_destroy(&mutex); return 1 ; } else if (pid == 0 ) { printf ("in the child, want to get the lock\n" ); pthread_mutex_lock(&mutex); printf ("can not run to here\n" ); pthread_mutex_unlock(&mutex); exit (0 ); } else { wait(NULL ); } pthread_join(id, NULL ); pthread_mutex_destroy(&mutex); return 0 ; }
pthread提供了一个专门的函数pthread_atfork,确保fork调用后父子进程都有一个清除的锁状态,定义如下:
1 2 #include <pthread.h> int pthread_atfork (void (*prepare)(void ), void (*parent)(void ), void (*child)(void )) ;
通过三个句柄来帮助清理互斥锁的状态。prepare句柄在fork调用创建出子进程之前被执行,用来锁住父进程中的互斥锁。parent句柄则是fork调用创建子进程之后,fork返回之前在父进程中执行,释放prepare中锁住的互斥锁。child句柄在fork返回前,在子进程中执行,释放prepare中锁住的互斥锁。
1 2 3 4 5 6 7 8 9 void prepare () { pthread_mutex_lock(&mutex); } void infork () { pthread_mutex_unlock(&mutex); } pthread_atfork(prepare, infork, infork);
在fork调用前加入如上代码,即可正常工作。
c) 线程和信号
每个线程都可以独立地设置信号掩码,在多线程环境中应该使用如下的pthread版本的sigprocmask函数来设置
1 2 3 #include <pthread.h> #include <signal.h> int pthread_sigmask (int how, const sigset_t *newmask, sigset_t *oldmask) ;
参数和sigprocmask完全相同。
定义一个专门的线程来处理所有的信号,如下两个步骤:
主线程创建其他子线程之前就调用pthread_sigmask设置好信号掩码,所有新创建的子线程将自动继承这个信号掩码。这样,所有线程都不会响应被屏蔽的信号了。
在某个线程中调用如下函数来等待信号并处理之。
1 2 #include <signal.h> int sigwait (const sigset_t *set , int *sig) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <signal.h> #include <errno.h> #define handle_error_en(en, msg) \ do {errno = en; perror(msg); exit(EXIT_FAILURE); } while (0) static void *sig_thread (void *arg) { sigset_t *set = (sigset_t *)arg; int s, sig; for (;;) { s = sigwait(set , &sig); if (s != 0 ) handle_error_en(s, "sigwait" ); printf ("signal handling thread got signal %d\n" , sig); } } int main () { pthread_t thread; sigset_t set ; int s; sigemptyset(&set ); sigaddset(&set , SIGQUIT); sigaddset(&set , SIGUSR1); s = pthread_sigmask(SIG_BLOCK, &set , NULL ); if (s != 0 ) handle_error_en(s, "pthread_sigmask" ); s = pthread_create(&thread, NULL , &sig_thread, (void *)&set ); if (s != 0 ) handle_error_en(s, "pthread_create" ); pause(); }
pthread还提供了下面的方法,可以明确地将一个信号发送给指定的线程:
1 2 #include <signal.h> int pthread_kill (pthread_t thread, int sig) ;
第17章 系统检测工具 讨论几个常用工具:tcpdump,nc,strace,lsof,vmstat,ifstat和mpstat
17.1 tcpdump